The purpose of this assignment is to serve as a simple warmup exercise and to serve as a practice "dry run" for the submission procedures of subsequent assignments. You'll have to write a bit of code but this assignment is mostly about the "mechanics" of setting up your Hadoop development environment. In addition to running Hadoop locally in either the Linux student CS environment or on your own machine, you'll also try running jobs on the Altiscale cluster.
The general setup is as follows: you will complete your assignments and check everything into a private GitHub repo. Shortly after the assignment deadline, we'll pull your repo for grading. Although we will be examining your solutions to assignment 0, it will not be graded per se.
I'm assuming you already have a GitHub account. If not, create one as soon as possible. Once you've signed up for an account, go and request an educational account. This will allow you to create private repos for free. Please do this as soon as possible since there may be delays in the request verification process.
Hadoop and Spark are already installed in
the linux.student.cs.uwaterloo.ca
environment (you just need to add some paths).
Alternatively, you may wish to install everything locally
on your own machine. For both, see the software page for
more details.
Bespin is a library that contains reference implementations of "big
data" algorithms in MapReduce and Spark. We'll be using it throughout
this course. Go and run
the Word Count in
MapReduce and Spark example as shown in the Bespin README (clone
and build the repo, download the data files, run word count in both
MapReduce in Spark, and verify output). Assuming you are
using linux.student.cs.uwaterloo.ca (or if you have
properly set up your local environment), this task should be as simple
as copying and pasting commands from the Bespin README.
When running Hadoop, you might get the following warning: "Unable to load native-hadoop library for your platform... using builtin-java classes where applicable". It's okay: no need to worry.
Create a private repo
called bigdata2016w. I'm assuming that you're
already familiar with Git and GitHub, but just in case, here
is how you
create a repo on GitHub. For "Who has access to this repository?",
make sure you click "Only the people I specify". If you've
successfully gotten an educational account (per above), you should be
able to create private repos for free. If you're not already familiar
with Git, there are plenty of good tutorials online: do a simple web
search and find one you like.
What you're going to do now is to copy the MapReduce word count
example into you own private repo. Start with
this pom.xml: copy it
into your bigdata2016w repo. The replace this line in
that file:
<groupId>ca.uwaterloo.cs.bigdata2016w.lintool</groupId>
Instead of lintool, substitute your GitHub
username. You'll be working in your own namespace, so in everything
that follows, substitute your own GitHub username in place
of lintool.
Next, copy:
bespin/src/main/java/io/bespin/java/mapreduce/wordcount/WordCount.java over to
bigdata2016w/src/main/java/ca/uwaterloo/cs/bigdata2016w/lintool/assignment0/WordCount.java.
Open up this new version of WordCount.java using a
text editor (or your IDE of choice) and change the Java package
to ca.uwaterloo.cs.bigdata2016w.lintool.assignment0.
Now, in the bigdata2016w/ base directory, you should
be able to run Maven to build your package:
$ mvn clean package
Once the build succeeds, you should be able to run the word count demo program in your own repository:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment0.WordCount \ -input data/Shakespeare.txt -output wc
You should be running this in the Linux student CS environment or
on your own machine. Note that you'll need to copy over the
Shakespeare collection in data/. The output should be
exactly the same as the same program in Bespin, but the difference
here is that the code is now in a repository under your control, in
your own private namespace.
Let's make a simple modification to word count: instead of counting
words, I want to count the occurrences of two-character prefixes of
words, i.e., the first two characters. That is, I want to know how
many words begin with "aa", "ab", "ac", etc., all the way to "zz"
(including special characters, etc.). Create a program
called PrefixCount in the
package ca.uwaterloo.cs.bigdata2016w.lintool.assignment0 that does this.
To be clear, the WordCount defines a "word" as
follows:
String w = itr.nextToken().toLowerCase().replaceAll("(^[^a-z]+|[^a-z]+$)", "");
Simply take whatever w.substring(0, 2) gives you as a
prefix. This means, of course, that you should ignore single
characters.
We should be able to run your program as follows:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment0.PrefixCount \ -input data/Shakespeare.txt -output cs489-2016w-lintool-a0-shakespeare
You shouldn't need to write more than a couple lines of code (beyond changing class names and other boilerplate). We'll go over the Hadoop API in more detail in class, but the changes should be straightforward.
Answer the following questions:
Question 1. In the Shakespeare collection, what are the three most frequent two character prefixes and how many times does each occur? (Remember when I mentioned "command line"-fu skills in class? This is where such skills will come in handy...)
Question 2. In the Shakespeare collection, how frequent does the prefix "li" occur?
You can run the above instructions using
check_assignment0_public_linux.py as follows:
$ wget http://lintool.github.io/bigdata-2016w/assignments/check_assignment0_public_linux.py $ ./check_assignment0_public_linux.py lintool
In fact, we'll be using exactly this script to check your assignment in the Linux Student CS environment. That is, make sure that your code runs there even if you do development on your own machine.
The software page has details on
getting started with the Altiscale cluster. Register your account and
follow instructions to set up ssh into the "workspace". Make sure
you've properly set up the proxy to view the cluster Resource Manager
(RM) webapp
at http://rm-ia.s3s.altiscale.com:8088/cluster/.
Getting access to the RM webapp is important—you'll need it to
track your job status and for debugging purposes.
Once you've ssh'ed into the workspace, check out Bespin and run word count:
$ hadoop jar target/bespin-0.1.0-SNAPSHOT.jar io.bespin.java.mapreduce.wordcount.WordCount \ -input /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt -output wc-jmr-combiner
Note that we're running word count over a larger collection here: a 10% sample of English Wikipedia totaling 1.3 GB (here's a chance to exercise your newly-acquired HDFS skills to confirm for yourself).
Question 3. Were you able to successfully run word count on the Altiscale cluster and get access to the Resource Manager webapp? (Yes or No)
Now switch into your own bigdata2016w/ repo and run
your prefix count program on the sample Wikipedia data:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment0.PrefixCount \ -input /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt -output cs489-2016w-lintool-a0-wiki
Question 4. In the sample Wikipedia collection, what are the three most frequent two character prefixes and how many times does each occur?
Question 5. In the sample Wikipedia collection, How frequent does the prefix "li" occur?
Note that the Altiscale cluster is a shared resource, and how fast your jobs complete will depend on how busy it is. You're advised to begin the assignment early as to avoid long job queues. "I wasn't able to complete the assignment because there were too many jobs running on the cluster" will not be accepted as an excuse if your assignment is late.
You can run the above instructions using
check_assignment0_public_altiscale.py as follows:
$ wget http://lintool.github.io/bigdata-2016w/assignments/check_assignment0_public_altiscale.py $ ./check_assignment0_public_altiscale.py lintool
In fact, we'll be using exactly this script to check your assignment on the Altiscale cluster.
At this point, you should have a GitHub
repo bigdata2016w/ and inside the repo, you should have
the word count program copied over from Bespin and the new prefix count
implementation, along with your pom.xml. Commit these
files. Next, create a file called assignment0.md
inside bigdata2016w/. In that file, put your answers to
the above questions (1—5). Use the Markdown annotation format: here's
a simple
guide.
Note: there is no need to commit data/
or target/ (or any results that you may have generated),
so your repo should be very compact — it should only have four
files: two Java source files, pom.xml,
and assignment0.md. You can add a .gitignore
file if you wish.
For this and all subsequent assignments, make sure everything is on the master branch. Push your repo to GitHub. You can verify that it's there by logging into your GitHub account in a web browser: your assignment should be viewable in the web interface.
For this (and the following assignments) there are two parts, one that can be completed locally, and another that requires the Altiscale cluster. For the first, make sure that your code runs in the Linux Student CS environment (even if you do development on your own machine), which is where we will be doing the grading. "But it runs on my laptop!" will not be accepted as an excuse if we can't get your code to run.
Almost there! Add the user teachtool a collaborator to your repo so that we can access it (under settings in the main web interface on your repo). Note: do not add my primary GitHub account lintool as a collaborator.
Finally, you need to tell us your GitHub account so we can link it to you. Submit your user name here.
And that's it!
To give you an idea of how we'll be grading this and future assignments—we will clone your repo and use the above check scripts:
check_assignment0_public_linux.py
in the Linux Student CS environment.check_assignment0_public_altiscale.py on the Altiscale cluster.We'll make sure the data files are in the right place, and once the code completes, we will verify the output. It is highly recommend that you run these check scripts: if it doesn't work for you, it won't work for us either.
As mentioned above, one main purpose of this assignment is to provide a practice "dry run" of how assignments will be submitted in the future. It is your responsibility to follow these instructions and learn the process: we will work with you to get the process sorted out for this assignment, but in subsequent assignments, you may be docked points for failing to conform to our expectations.
By now, you should already be familiar with the Hadoop execution
environment (e.g., submitting jobs) and using Maven to organize your
assignments. You will be working in the same repo as before, except
that everything should go into the package namespace
ca.uwaterloo.cs.bigdata2016w.lintool.assignment1
(obviously, replace lintool with your actual GitHub
username.
Note that the point of assignment 0 was to familiarize your with GitHub and the Hadoop development environment. We will work through issues with you, but starting this assignment, excuses along the lines of "I couldn't get my repo set up properly", "I couldn't figure out how to push my assignment to GitHub", etc. will not be accepted. It is your responsibility to sort through any mechanics issue you have.
Before staring this assignment, it is highly recommended that you look at the implementations of bigram relative frequency and co-occurrence matrix computation in Bespin.
In this assignment you'll be computing pointwise mutual information, which is a function of two events x and y:
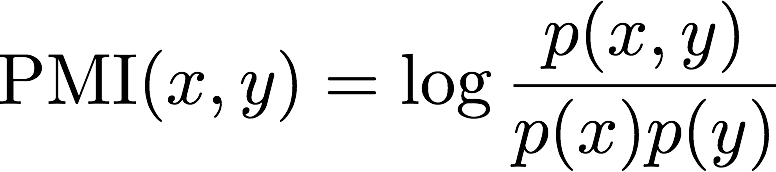
The larger the magnitude of PMI for x and y is, the more information you know about the probability of seeing y having just seen x (and vice-versa, since PMI is symmetrical). If seeing x gives you no information about seeing y, then x and y are independent and the PMI is zero.
Write a program (two separate implementations, actually—more details below)
that computes the PMI of words in the
data/Shakespeare.txt collection that's used in the Bespin
demos and the previous assignment. Your implementation should be in Java. To be more specific, the event
we're after is x occurring on a line in the file (the denominator above) or x
and y co-occurring on a line (the numerator above). That is, if a line contains "A B
C", then the co-occurring pairs are:
If the line contains "A A B C", the co-occurring pairs are still the same as above; same if the line contains "A B C A B C"; or any combinations of A, B, and C in any order.
A few additional important details:
Use the same definition of "word" as in the word count demo. Just to make sure we're all on the same page, use this as the starting point of your mapper:
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = ((Text) value).toString();
StringTokenizer itr = new StringTokenizer(line);
int cnt = 0;
Set set = Sets.newHashSet();
while (itr.hasMoreTokens()) {
cnt++;
String w = itr.nextToken().toLowerCase().replaceAll("(^[^a-z]+|[^a-z]+$)", "");
if (w.length() == 0) continue;
set.add(w);
if (cnt >= 100) break;
}
String[] words = new String[set.size()];
words = set.toArray(words);
// Your code goes here...
}
You will build two versions of the program (put both in
package ca.uwaterloo.cs.bigdata2016w.lintool.assignment1):
PairsPMI.StripesPMI.Since PMI is symmetrical, PMI(x, y) = PMI(y, x). However, it's
actually easier in your implementation to compute both values, so
don't worry about duplicates. Also, use TextOutputFormat
so the results of your program are human readable.
Make sure that the pairs implementation and the stripes implementation give the same answers!
Answer the following questions:
Question 1. (6 points) Briefly describe in prose your solution, both the pairs and stripes implementation. For example: how many MapReduce jobs? What are the input records? What are the intermediate key-value pairs? What are the final output records? A paragraph for each implementation is about the expected length.
Question 2. (2 points) What is the running time of the complete pairs
implementation? What is the running time of the complete stripes
implementation? (Tell me where you ran these experiments,
e.g., linux.student.cs.uwaterloo.ca or your own
laptop.)
Question 3. (2 points) Now disable all combiners. What is the running
time of the complete pairs implementation now? What is the running
time of the complete stripes implementation? (Tell me where you ran
these experiments, e.g., linux.student.cs.uwaterloo.ca or
your own laptop.)
Question 4. (3 points) How many distinct PMI pairs did you extract?
Question 5. (3 points) What's the pair (x, y) (or pairs if there are ties) with the highest PMI? Write a sentence or two to explain why such a high PMI.
Question 6. (6 points) What are the three words that have the highest PMI with "tears" and "death"? And what are the PMI values?
Note that you can compute the answer to questions 4—6 however you wish: a helper Java program, a Python script, command-line one-liner, etc.
Now, on the Altiscale cluster, run your pairs and stripes
implementation on the sample Wikipedia collection stored on HDFS
at /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt. Note
that in the Wikipedia collection, each article is on a line, so
we're computing co-occurring words in (the beginning of) the article. Also, the
"first 100 words" restriction will definitely apply here (whereas in
the Shakespeare collection, all the lines contained fewer than 100
words, so it was a no-op).
Make sure your code runs on this larger dataset. Assuming that there aren't many competing jobs on the cluster, your programs should not take more than 20 minutes to run. If your job is taking much longer than that, then please kill it so it doesn't waste resources and slow other people's jobs down. Obviously, if the cluster is really busy or if there's a long list of queued jobs, your job will take longer, so use your judgement here. The only point is: be nice. It's a shared resource, and let's not let runaway jobs slow everyone down.
One final detail, set your MapReduce job parameters as follows:
job.getConfiguration().setInt("mapred.max.split.size", 1024 * 1024 * 64);
job.getConfiguration().set("mapreduce.map.memory.mb", "3072");
job.getConfiguration().set("mapreduce.map.java.opts", "-Xmx3072m");
job.getConfiguration().set("mapreduce.reduce.memory.mb", "3072");
job.getConfiguration().set("mapreduce.reduce.java.opts", "-Xmx3072m");
What the last four options do is fairly obvious. The first sets the maximum split size to be 64 MB. What effect does that have? (Hint, consider the physical execution of MapReduce programs we discussed in class)
Question 7. (6 points) In the Wikipedia sample, what are the three words that have the highest PMI with "waterloo" and "toronto"? And what are the PMI values?
It's worth noting again: the Altiscale cluster is a shared resource, and how fast your jobs complete will depend on how busy it is. You're advised to begin the assignment early as to avoid long job queues. "I wasn't able to complete the assignment because there were too many jobs running on the cluster" will not be accepted as an excuse if your assignment is late.
Please follow these instructions carefully!
Make sure your repo has the following items:
bigdata2016w/assignment1.md.ca.uwaterloo.cs.bigdata2016w.lintool.assignment1.When grading, we will pull your repo and build your code:
$ mvn clean package
Your code should build successfully. We are then going to check your code (both the pairs and stripes implementations).
We're going to run your code on the Linux student CS environment as follows (we will make sure the collection is there):
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment1.PairsPMI \ -input data/Shakespeare.txt -output cs489-2016w-lintool-a1-shakespeare-pairs -reducers 5 $ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment1.StripesPMI \ -input data/Shakespeare.txt -output cs489-2016w-lintool-a1-shakespeare-stripes -reducers 5
Make sure that your code runs in the Linux Student CS environment (even if you do development on your own machine), which is where we will be doing the grading. "But it runs on my laptop!" will not be accepted as an excuse if we can't get your code to run.
You can run the above instructions using
check_assignment1_public_linux.py.
We're going to run your code on the Altiscale cluster as follows:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment1.PairsPMI \ -input /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt -output cs489-2016w-lintool-a1-wiki-pairs -reducers 5 $ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment1.StripesPMI \ -input /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt -output cs489-2016w-lintool-a1-wiki-stripes -reducers 5
You can run the above instructions using
check_assignment1_public_altiscale.py.
Important: Make sure that your code accepts the command-line parameters above! That is, make sure the check scripts work!
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", verify everything above works by performing a clean clone of your repo and going through the steps above.
That's it! There's no need to send us anything—we already know your username from the first assignment. Note that everything should be committed and pushed to origin before the deadline.
Writable datatypes that you might find
useful. (Feel free to use, but assignment can be completed
without it.)This assignment is worth a total of 50 points, broken down as follows:
check_assignment1_public_linux.py
(on Linux Student CS)
an check_assignment1_public_altiscale.py
(on Altiscale cluster) successfully without any errors.In this assignment you will "port" the MapReduce implementations of
the bigram frequency count program
from Bespin over to Spark (in
Scala). Your starting points
are ComputeBigramRelativeFrequencyPairs
and ComputeBigramRelativeFrequencyStripes in
package io.bespin.java.mapreduce.bigram (in Java).
You are welcome to build on the BigramCount (Scala)
implementation here
for tokenization and "boilerplate" code like command-line argument
parsing. To be consistent in tokenization, you should copy over
the Tokenizer trait
here. You'll
also need to grab missing Maven dependencies
from here.
Put your code in the
package ca.uwaterloo.cs.bigdata2016w.lintool.assignment2. Since
you'll be writing Scala code, your source files should go
into src/main/scala/ca/uwaterloo/cs/bigdata2016w/lintool/assignment2/. Note
that the repository is designed so that Scala/Spark code will also
compile with the same Maven build command:
$ mvn clean package
Following the Java implementations, you will write both a "pairs" and a "stripes" implementation in Spark. Not that although Spark has a different API than MapReduce, the algorithmic concepts are still very much applicable. Your pairs and stripes implementation should follow the same logic as in the MapReduce implementations. In particular, your program should only take one pass through the input data.
Make sure your implementation runs in the Linux student CS
environment on the Shakespeare collection and also on sample
Wikipedia
file /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt
on HDFS in the Altiscale cluster. Note that submitting Spark jobs on
the Altiscale cluster requires a rather arcane command-line
invocation see the software page for
more details.
You can verify the correctness of your algoritm by comparing the output of the MapReduce implementation with your Spark implementation. The output should be the same.
Clarification on terminology: informally, we often refer to
"mappers" and "reducers" in the context of Spark. That's a shorthand
way of saying map-like transformations
(map, flatMap, filter, mapPartitions,
etc.) and reduce-like transformations
(e.g., reduceByKey, groupByKey, aggregateByKey,
etc.). Hopefully it's clear from lecture that while Spark represents a
generalization of MapReduce, the notions of per-record processing
(i.e., map-like transformation) and grouping/shuffling (i.e.,
reduce-like transformations) are shared across both frameworks.
Please follow these instructions carefully!
The pairs and stripes implementation should be in
package ca.uwaterloo.cs.bigdata2016w.lintool.assignment2;
your Scala code should be
in src/main/scala/ca/uwaterloo/cs/bigdata2016w/lintool/assignment2/.
There are no questions to answer in this assignment unless there is
something you would like to communicate with us, and if so, put it
in assignment2.md.
When grading, we will pull your repo and build your code:
$ mvn clean package
Your code should build successfully. We are then going to check your code (both the pairs and stripes implementations).
We're going to run your code on the Linux student CS environment as follows (we will make sure the collection is there):
$ spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment2.ComputeBigramRelativeFrequencyPairs \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input data/Shakespeare.txt --output cs489-2016w-lintool-a2-shakespeare-pairs --reducers 5 $ spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment2.ComputeBigramRelativeFrequencyStripes \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input data/Shakespeare.txt --output cs489-2016w-lintool-a2-shakespeare-stripes --reducers 5
Make sure that your code runs in the Linux Student CS environment (even if you do development on your own machine), which is where we will be doing the grading. "But it runs on my laptop!" will not be accepted as an excuse if we can't get your code to run.
We're going to run your code on the Altiscale cluster as follows
(note we add --num-executors 10 to specify the number of
executors; also note that we use the my-spark-submit
launch script—see the software
page for details):
$ my-spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment2.ComputeBigramRelativeFrequencyPairs --num-executors 10 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt \ --output cs489-2016w-lintool-a2-wiki-pairs --reducers 10 $ my-spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment2.ComputeBigramRelativeFrequencyStripes --num-executors 10 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt \ --output cs489-2016w-lintool-a2-wiki-stripes --reducers 10
Important: Make sure that your code accepts the command-line parameters above!
Brief explanation about the relationship
between --num-executors
and --reducers. The --num-executors flag
specifies the number of Spark workers that you allocate for this
particular job. The --reducers flag is the amount of
parallelism that you set in your program in the reduce
stage. If --num-executors is larger
than --reducers, some of the workers will be sitting
idle, since you've allocated more workers for the job than the
parallelism you've specified in your
program. If --reducers is larger
than --num-executors, then your reduce tasks will queue
up at the workers, i.e., a worker will be assigned more than one
reduce task. In the above example we set the two equal.
Note that the setting of these two parameters should not affect the correctness of your program. The setting of ten above is a reasonable middle ground between having your jobs finish in a reasonable amount of time and not monopolizing cluster resources.
A related but still orthogonal concept is partitions. Partitions describes the physical division of records across workers during execution. When reading from HDFS, the number of HDFS blocks determines the number of partitions in your RDD. When you apply a reduce-like transformation, you can optionally specify the number of partitions (or Spark applies a default) — in this case, the number of partitions is equal to the number of reducers.
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", we would recommend that you verify everything above works by performing a clean clone of your repo and going through the steps above.
That's it!
This assignment is worth a total of 20 points, broken down as follows:
This assignment is to be completed in MapReduce in Java. You will
be working in the same repo as before, except that everything should
go into the package namespace
ca.uwaterloo.cs.bigdata2016w.lintool.assignment3
(obviously, replace lintool with your actual GitHub
username.
Look at the inverted indexing and boolean retrieval implementation
in Bespin. Make sure you understand the
code. Starting from the inverted indexing
baseline BuildInvertedIndex, modify the indexer code in
the following ways:
1. Index Compression. The index should be compressed using
VInts:
see org.apache.hadoop.io.WritableUtils. You should also
use gap-compression techniques as appropriate.
2. Buffering postings. The baseline indexer implementation currently buffers and sorts postings in the reducer, which as we discussed in class is not a scalable solution. Address this scalability bottleneck using techniques we discussed in class and in the textbook.
3. Term partitioning. The baseline indexer implementation currently uses only one reducer and therefore all postings lists are shuffled to the same node and written to HDFS in a single partition. Change this so we can specify the number of reducers (hence, partitions) as a command-line argument. This is, of course, easy to do, but we need to make sure that the searcher understands this partitioning also.
Note: The major scalability issue is buffering uncompressed postings in memory. In your solution, you'll still end up buffering each postings list, but in compressed form (raw bytes, no additional object overhead). This is fine because if you use the right compression technique, the postings lists are quite small. As a data point, on a collection of 50 million web pages, 2GB heap is more than enough for a full positional index (and in this assignment you're not asked to store positional information in your postings).
To go into a bit more detail: in the reference implementation, the
final key type is PairOfWritables<IntWritable,
ArrayListWritable<PairOfInts>>. The most obvious idea
is to change that into something
like PairOfWritables<VIntWritable,
ArrayListWritable<PairOfVInts>>. This does not work!
The reason is that you will still be materializing each posting, i.e.,
all PairOfVInts objects in memory. This translates into a
Java object for every posting, which is wasteful in terms of memory
usage and will exhaust memory pretty quickly as you scale. In other
words, you're still buffering objects—just inside
the ArrayListWritable.
This new indexer should be
named BuildInvertedIndexCompressed. This new class should
be in the
package ca.uwaterloo.cs.bigdata2016w.lintool.assignment3. Make
sure it works on the Shakespeare collection.
Modify BooleanRetrieval so that it works with the new
compressed indexes. Name this new
class BooleanRetrievalCompressed. This new class should
be in the same package as above and give the same
output as the old version.
Use BuildInvertedIndex
and BooleanRetrieval from Bespin as your starting
points. That is, copy over into your repo, rename, and begin your
assignment from there. Don't unnecessarily change code not directly
related to points #1-#3 above. In particular, do not change how
the documents are tokenized, etc. in BuildInvertedIndex
(otherwise there's no good way to check for the correctness of your
algorithm). Also, do not change the fetchLine
method in BooleanRetrieval so that everyone's output
looks the same.
In more detail, make sure that you can build the inverted index with the following command (make sure your implementation runs in the Linux student CS environment, as that is where we will be doing the grading):
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment3.BuildInvertedIndexCompressed \ -input data/Shakespeare.txt -output cs489-2016w-lintool-a3-index-shakespeare -reducers 4
We should be able to control the number of partitions (#3 above)
with the -reducers option. That is, the code should give
the correct results no matter what we set the value to.
Once we build the index, we should then be able to run a boolean
query as follows (in exactly the same manner
as BooleanRetrieval in Bespin):
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment3.BooleanRetrievalCompressed \ -index cs489-2016w-lintool-a3-index-shakespeare -collection data/Shakespeare.txt \ -query "outrageous fortune AND" $ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment3.BooleanRetrievalCompressed \ -index cs489-2016w-lintool-a3-index-shakespeare -collection data/Shakespeare.txt \ -query "white red OR rose AND pluck AND"
Of course, we will try your program with additional queries to verify its correctness.
Answer the following question:
Question 1. What is the size of your compressed
index for Shakespeare collection? Just so we're using the same units,
report the output of du -h.
Now let's try running your implementation on the Altiscale cluster,
on the sample Wikipedia
file /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt
on HDFS:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment3.BuildInvertedIndexCompressed \ -input /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt \ -output cs489-2016w-lintool-a3-index-wiki -reducers 4
And let's try running a query:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment3.BooleanRetrievalCompressed \ -index cs489-2016w-lintool-a3-index-wiki \ -collection /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt \ -query "waterloo stanford OR cheriton AND" $ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment3.BooleanRetrievalCompressed \ -index cs489-2016w-lintool-a3-index-wiki \ -collection /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt \ -query "internet startup AND canada AND ontario AND"
Answer the following questions:
Question 2. What is the size of your compressed
index for the sample Wikipedia collection? Just so we're using the
same units, report the output of hadoop fs -du -h.
Question 3. What are the Wikipedia articles (just the
article titles) retrieved in response to the query "waterloo
stanford OR cheriton AND"?
Question 4. What are the Wikipedia articles (just
the article titles) retrieved in response to the query "internet
startup AND canada AND ontario AND"?
Please follow these instructions carefully!
Make sure your repo has the following items:
bigdata2016w/assignment3.md.ca.uwaterloo.cs.bigdata2016w.lintool.assignment3.Make sure your implementation runs in the Linux student CS
environment on the Shakespeare collection and also on sample Wikipedia
file /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt
on HDFS in the Altiscale cluster, per above.
Specifically, we will clone your repo and use the below check scripts:
check_assignment3_public_linux.py
in the Linux Student CS environment.check_assignment3_public_altiscale.py on the Altiscale cluster.When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", we would recommend that you verify everything above works by performing a clean clone of your repo and run the public check scripts.
That's it!
This assignment is worth a total of 50 points, broken down as follows:
check_assignment3_public_linux.py
(on Linux Student CS)
an check_assignment3_public_altiscale.py
(on Altiscale cluster) successfully without any errors.For this assignment, you will be working in the same repo as
before, except that everything should go into the package namespace
ca.uwaterloo.cs.bigdata2016w.lintool.assignment4
(obviously, replace lintool with your actual GitHub
username.
Begin by taking the time to understand
the PageRank
reference implementation in Bespin
(particularly RunPageRankBasic). For this assignment,
you are going to implement multiple-source personalized PageRank. As
we discussed in class, personalized PageRank is different from
ordinary PageRank in a few respects:
Here are some publications about personalized PageRank if you're interested. They're just provided for background; neither is necessary for completing the assignment.
Your implementation is going to run multiple personalized PageRank
computations in parallel, one with respect to each source. The sources
will be specified on the command line. This means that each
PageRank node object (i.e., Writable) is going to contain
an array of PageRank values.
Here's how the implementation is going to work: it largely follows
the reference implementation of RunPageRankBasic. You
must make your implementation work with respect to the command-line
invocations specified below.
First, convert the adjacency list into PageRank node records:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.BuildPersonalizedPageRankRecords \ -input data/p2p-Gnutella08-adj.txt -output cs489-2016w-lintool-a4-Gnutella-PageRankRecords \ -numNodes 6301 -sources 367,249,145
The -sources option specifies the source nodes for the
personalized PageRank computations. In this case, we're running three
computations in parallel, with respect to node ids 367, 249, and
145. You can expect the option value to be in the form of a
comma-separated list, and that all node ids actually exist in the
graph. The list of source nodes may be arbitrarily long, but for
practical purposes we won't test your code with more than a few.
Since we're running three personalized PageRank computations in parallel, each PageRank node is going to hold an array of three values, the personalized PageRank values with respect to the first source, second source, and third source. You can expect the array positions to correspond exactly to the position of the node id in the source string.
Next, partition the graph (hash partitioning) and get ready to iterate:
$ hadoop fs -mkdir cs489-2016w-lintool-a4-Gnutella-PageRank $ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.PartitionGraph \ -input cs489-2016w-lintool-a4-Gnutella-PageRankRecords \ -output cs489-2016w-lintool-a4-Gnutella-PageRank/iter0000 -numPartitions 5 -numNodes 6301
After setting everything up, iterate multi-source personalized PageRank:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.RunPersonalizedPageRankBasic \ -base cs489-2016w-lintool-a4-Gnutella-PageRank -numNodes 6301 -start 0 -end 20 -sources 367,249,145
Note that the sources are passed in from the command-line again. Here, we're running twenty iterations.
Finally, run a program to extract the top ten personalized PageRank values, with respect to each source.
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.ExtractTopPersonalizedPageRankNodes \ -input cs489-2016w-lintool-a4-Gnutella-PageRank/iter0020 -output cs489-2016w-lintool-a4-Gnutella-PageRank-top10 \ -top 10 -sources 367,249,145
The above program should print the following answer to stdout:
Source: 367 0.35257 367 0.04181 264 0.03889 266 0.03888 559 0.03883 5 0.03860 1317 0.03824 666 0.03817 7 0.03799 4 0.00850 249 Source: 249 0.34089 249 0.04034 251 0.03721 762 0.03688 123 0.03686 250 0.03668 753 0.03627 755 0.03623 351 0.03622 983 0.00949 367 Source: 145 0.36937 145 0.04195 1317 0.04120 265 0.03847 390 0.03606 367 0.03566 246 0.03525 667 0.03519 717 0.03513 149 0.03496 2098
To make the final output easier to read, in the
class ExtractTopPersonalizedPageRankNodes, use the
following format to print each (personalized PageRank value, node id)
pair:
String.format("%.5f %d", pagerank, nodeid)
This will generate the final results in the same format as above. Also note: print actual probabilities, not log probabilities—although during the actual PageRank computation keep values as log probabilities.
The final class ExtractTopPersonalizedPageRankNodes
does not need to be a MapReduce job (but it does need to read from
HDFS). Obviously, the other classes need to run MapReduce jobs.
The reference implementation of PageRank in Bespin has many options: you can either use in-mapper combining or ordinary combiners. In your implementation, use ordinary combiners. Also, the reference implementation has an option to either use range partitioning or hash partitioning: you only need to implement hash partitioning. You can start with the reference implementation and remove code that you don't need (see #2 below).
To help you out, there's a small helper program in Bespin that computes personalized PageRank using a sequential algorithm. Use it to check your answers:
$ hadoop jar target/bespin-0.1.0-SNAPSHOT.jar io.bespin.java.mapreduce.pagerank.SequentialPersonalizedPageRank \ -input data/p2p-Gnutella08-adj.txt -source 367
Note that this isn't actually a MapReduce job; we're simply using
Hadoop to run the main for convenience. The values from
your implementation should be pretty close to the output of the above
program, but might differ a bit due to convergence issues. After 20
iterations, the output of the MapReduce implementation should match to
at least the fourth decimal place.
This is complex assignment. We would suggest breaking the implementation into the following steps:
-sources w,x,y,z, simply
ignore x,y,z and run personalized PageRank with respect
to w. This can be accomplished with the
existing PageRankNode, which holds a single floating
point value.PageRankNode class to store an array of
floats (length of array is the number of sources) instead of a single
float. Make sure single-source personalized PageRank still runs.In particular, #3 is a nice checkpoint. If you're not able to get the multiple-source personalized PageRank to work, at least completing the single-source implementation will allow us to give you partial credit.
Once you get your implementation working and debugged in the Linux
environment, you're going to run your code on a non-trivial graph: the
link structure of (all of) Wikipedia. The adjacency lists are stored
in /shared/cs489/data/wiki-adj on HDFS. The graph has
16,117,779 vertices and 155,472,640 edges.
First, convert the adjacency list into PageRank node records:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.BuildPersonalizedPageRankRecords \ -input /shared/cs489/data/wiki-adj -output cs489-2016w-lintool-a4-wiki-PageRankRecords \ -numNodes 16117779 -sources 73273,73276
Next, partition the graph (hash partitioning) and get ready to iterate:
$ hadoop fs -mkdir cs489-2016w-lintool-a4-wiki-PageRank $ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.PartitionGraph \ -input cs489-2016w-lintool-a4-wiki-PageRankRecords \ -output cs489-2016w-lintool-a4-wiki-PageRank/iter0000 -numPartitions 10 -numNodes 16117779
After setting everything up, iterate multi-source personalized PageRank:
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.RunPersonalizedPageRankBasic \ -base cs489-2016w-lintool-a4-wiki-PageRank -numNodes 16117779 -start 0 -end 20 -sources 73273,73276
On the Altiscale cluster, each iteration shouldn't take more than a couple of minutes to complete. If it's taking more than five minutes per iteration, you're doing something wrong.
Finally, run a program to extract the top ten personalized PageRank values, with respect to each source.
$ hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.ExtractTopPersonalizedPageRankNodes \ -input cs489-2016w-lintool-a4-wiki-PageRank/iter0020 -output cs489-2016w-lintool-a4-wiki-PageRank-top10 \ -top 10 -sources 73273,73276
In the example above, we're running personalized PageRank with
respect to two sources: 73273 and 73276. What articles do these ids
correspond to? There's a file on HDFS
at /shared/cs489/data/wiki-titles.txt that provides the
answer. How do you know if your implementation is correct? You can
sanity check your results by taking the ids and looking up the
articles that they correspond to. Do the results make sense?
Please follow these instructions carefully!
Make sure your repo has the following items:
bigdata2016w/assignment4.md (more below).ca.uwaterloo.cs.bigdata2016w.lintool.assignment4.Make sure your implementation runs in the Linux student CS environment on the Gnutella graph and on the Wikipedia graph on the Altiscale cluster.
In bigdata2016w/assignment4.md, tell us if you were
able to successfully complete the assignment. This is in case we can't
get your code to run, we need to know if it is because you weren't able
to complete the assignment successfully, or if it is due to some other
issue. If you were not able to implement everything, describe how far
you've gotten. Feel free to use this space to tell us additional
things we should look for in your implementation.
Also, in this file, copy the output of your implementation on the Altiscale cluster, i.e., personalized PageRank with respect to vertices 73273 and 73276. This will give us something to look at and check if we can't get your code to run successfully. Something that looks like this:
Source: 73273 0.XXXXX XXX ... Source: 73276 0.XXXXX XXX ...
When grading, we will clone your repo and use the below check scripts:
check_assignment4_public_linux.py
in the Linux Student CS environment.check_assignment4_public_altiscale.py
on the Altiscale cluster.When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", we would recommend that you verify everything above works by performing a clean clone of your repo and run the public check scripts.
That's it!
The entire assignment is worth 55 points:
In our private check scripts, we will specify arbitrary source nodes to verify the correctness of your implementation.
Note that this grading scheme discretizes each component of the assignment. For example, if you implement everything and it works correctly on the Linux Student CS environment, but can't get it to scale on the Altiscale cluster to the larger graph, you'll receive 35 out of 55 points. On the other hand, if you implement single-source personalized PageRank correctly and it runs in both the Linux Student CS environment and Altiscale, you will receive 25 out of 55 points. And combinations thereof.
In this assignment you'll be hand-crafting Spark programs that implement SQL queries in a data warehousing scenario. Various SQL-on-Hadoop solutions share in providing an SQL query interface on data stored in HDFS via an intermediate execution framework. For example, Hive queries are "compiled" into MapReduce jobs; SparkSQL queries rely on Spark processing primitives for query execution. In this assignment, you'll play the role of mediating between SQL queries and the underlying execution framework (Spark). In more detail, you'll be given a series of SQL queries, and for each you'll have to hand-craft a Spark program that corresponds to each query.
Important: You are not allowed to use the Dataframe API or
Spark SQL to complete this assignment. You must write code to manipulate raw RDDs.
Furthermore, you are not allowed to use join and
closely-related transformations in Spark for this assignment, because
otherwise it defeats the point of the exercise. The assignment will
guide you toward what we are looking for, but if you have any
questions as to what is allowed or not, ask!
We will be working with data from the TPC-H benchmark in this assignment. The Transaction Processing Performance Council (TPC) is a non-profit organization that defines various database benchmarks so that database vendors can evaluate the performance of their products fairly. TPC defines the "rules of the game", so to speak. TPC defines various benchmarks, of which one is TPC-H, for evaluating ad-hoc decision support systems in a data warehousing scenario. The current version of the TPC-H benchmark is located here. You'll want to skim through this (long) document; the most important part is the entity-relationship diagram of the data warehouse on page 13. Throughout the assignment you'll likely be referring to it, as it will help you make sense of the queries you are running.
The TPC-H benchmark comes with a data generator, and we have
generated some data for
you here
(TPC-H-0.1-TXT.tar.gz). For the first
part of the assignment where you will be working with Spark locally,
you will run your queries against this data.
Download and unpack the data above: you will see a number of text files,
each corresponding to a table in the TPC-H schema. The files are
delimited by |. You'll notice that some of the fields,
especially the text fields, are gibberish—that's normal, since
the data are randomly generated.
Implement the following seven SQL queries, running on
the TPC-H-0.1-TXT data. Each SQL query is
accompanied by a written description of what the query does; if there
are any ambiguities in the language, you can always assume that the
SQL query is correct. Each of your query will be a separate Spark
program. Put your code in the package
ca.uwaterloo.cs.bigdata2016w.lintool.assignment5, in the
same repo that you've been working in all semester. Since you'll be
writing Scala code, your source files should go into
src/main/scala/ca/uwaterloo/cs/bigdata2016w/lintool/assignment5/.
Obviously, replace lintool with your actual GitHub
username.
Q1: How many items were shipped on a particular date? This corresponds to the following SQL query:
select count(*) from lineitem where l_shipdate = 'YYYY-MM-DD';
Write a program such that when we execute the following command:
spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment5.Q1 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input TPC-H-0.1-TXT --date '1996-01-01'
the answer to the above SQL query will be printed to stdout (on the console where the above command is executed), in a line that matches the following regular expression:
ANSWER=\d+
The output of the query can contain logging and debug information, but there must be a line with the answer in exactly the above format.
The value of the
--input argument is the directory that contains the
plain-text tables. The value of the --date argument
corresponds to the l_shipdate predicate in the where
clause in the SQL query. You need to anticipate dates of the
form YYYY-MM-DD, YYYY-MM, or
just YYYY, and your query needs to give the correct
answer depending on the date format. You can assume that a valid date
(in one of the above formats) is provided, so you do not need to
perform input validation.
Q2: Which clerks were responsible for processing items that were shipped on a particular date? List the first 20 by order key. This corresponds to the following SQL query:
select o_clerk, o_orderkey from lineitem, orders where l_orderkey = o_orderkey and l_shipdate = 'YYYY-MM-DD' order by o_orderkey asc limit 20;
Write a program such that when we execute the following command:
spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment5.Q2 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input TPC-H-0.1-TXT --date '1996-01-01'
the answer to the above SQL query will be printed to stdout (on the console where the above command is executed), as a sequence of tuples in the following format:
(o_clerk,o_orderkey) (o_clerk,o_orderkey) ...
That is, each tuple is comma-delimited and surrounded by parentheses. Everything described in Q1 about dates applies here as well.
In the design of this data warehouse, the lineitem
and orders tables are not likely to fit in
memory. Therefore, the only scalable join approach is the reduce-side
join. You must implement this join in Spark using
the cogroup transformation.
Q3: What are the names of parts and suppliers of items shipped on a particular date? List the first 20 by order key. This corresponds to the following SQL query:
select l_orderkey, p_name, s_name from lineitem, part, supplier where l_partkey = p_partkey and l_suppkey = s_suppkey and l_shipdate = 'YYYY-MM-DD' order by l_orderkey asc limit 20;
Write a program such that when we execute the following command:
spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment5.Q3 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input TPC-H-0.1-TXT --date '1996-01-01'
the answer to the above SQL query will be printed to stdout (on the console where the above command is executed), as a sequence of tuples in the following format:
(l_orderkey,p_name,s_name) (l_orderkey,p_name,s_name) ...
That is, each tuple is comma-delimited and surrounded by parentheses. Everything described in Q1 about dates applies here as well.
In the design of this data warehouse, it is assumed that
the part and supplier tables will fit in
memory. Therefore, it is possible to implement a hash join. For this
query, you must implement a hash join in Spark with broadcast
variables.
Q4: How many items were shipped to each country on a particular date? This corresponds to the following SQL query:
select n_nationkey, n_name, count(*) from lineitem, orders, customer, nation where l_orderkey = o_orderkey and o_custkey = c_custkey and c_nationkey = n_nationkey and l_shipdate = 'YYYY-MM-DD' group by n_nationkey, n_name order by n_nationkey asc;
Write a program such that when we execute the following command:
spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment5.Q4 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input TPC-H-0.1-TXT --date '1996-01-01'
the answer to the above SQL query will be printed to stdout (on the console where the above command is executed). Format the output in the same manner as with the above queries: one tuple per line, where each tuple is comma-delimited and surrounded by parentheses. Everything described in Q1 about dates applies here as well.
Implement this query with different join techniques as you see
fit. You can assume that the lineitem
and orders table will not fit in memory, but you can
assume that the customer and nation tables
will both fit in memory. For this query, the performance as well as
the scalability of your implementation will contribute to the
grade.
Q5: This query represents a very simple end-to-end ad hoc
analysis task: Related to Q4, your boss has asked you to
compare shipments to Canada vs. the United States by month, given all
the data in the data warehouse. You think this request is best
fulfilled by a line graph, with two lines (one representing the US and
one representing Canada), where the x-axis is the year/month and
the y axis is the volume, i.e., count(*).
Generate this graph for your boss.
First, write a program such that when we execute the following command:
spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment5.Q5 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input TPC-H-0.1-TXT
the raw data necessary for the graph will be printed to stdout (on the console where the above command is executed). Format the output in the same manner as with the above queries: one tuple per line, where each tuple is comma-delimited and surrounded by parentheses.
Next, create this actual graph: use whatever tool you are comfortable with, e.g., Excel, gnuplot, etc.
Q6: This is a slightly modified version of TPC-H Q1 "Pricing Summary Report Query". This query reports the amount of business that was billed, shipped, and returned:
select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice*(1-l_discount)) as sum_disc_price, sum(l_extendedprice*(1-l_discount)*(1+l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from lineitem where l_shipdate = 'YYYY-MM-DD' group by l_returnflag, l_linestatus;
Write a program such that when we execute the following command:
spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment5.Q6 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input TPC-H-0.1-TXT --date '1996-01-01'
the answer to the above SQL query will be printed to stdout (on the console where the above command is executed). Format the output in the same manner as with the above queries: one tuple per line, where each tuple is comma-delimited and surrounded by parentheses. Everything described in Q1 about dates applies here as well.
Implement this query as efficiently as you can, using all of the optimizations we discussed in lecture. You will only get full points for this question if you exploit all the optimization opportunities that are available.
Q7: This is a slightly modified version of TPC-H Q3 "Shipping Priority Query". This query retrieves the 10 unshipped orders with the highest value:
select c_name, l_orderkey, sum(l_extendedprice*(1-l_discount)) as revenue, o_orderdate, o_shippriority from customer, orders, lineitem where c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < "YYYY-MM-DD" and l_shipdate > "YYYY-MM-DD" group by c_name, l_orderkey, o_orderdate, o_shippriority order by revenue desc limit 10;
Write a program such that when we execute the following command:
spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment5.Q7 \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input TPC-H-0.1-TXT --date '1996-01-01'
the answer to the above SQL query will be printed to stdout (on the
console where the above command is executed).
Format the output in the same manner as with the above queries: one
tuple per line, where each tuple is comma-delimited and surrounded by
parentheses. Here you can assume that the date argument is only in the
format YYYY-MM-DD and that it is a valid date.
Implement this query as efficiently as you can, using all of the optimizations we discussed in lecture. Plan you joins as you see fit, keeping in mind above assumptions on what will and will not fit in memory. You will only get full points for this question if you exploit all the optimization opportunities that are available.
Once you get your implementation working and debugged in the Linux
environment, run your code on a larger TCP-H dataset, located on HDFS
at /shared/cs489/data/TPC-H-10-TXT. Make sure that all
seven queries above run correctly on this larger dataset.
On the Altiscale cluster, we will run your code with the following command-line parameters (same for Q1-Q7):
my-spark-submit --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment5.Q1 --num-executors 10 --driver-memory 2g --executor-memory 2G \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input /shared/cs489/data/TPC-H-10-TXT --date '1996-01-01'
In this configuration, your programs shouldn't take more than a couple of minutes. If it's taking more than five minutes, you're probably doing something wrong.
Important: In your my-spark-submit script, make
sure you set --deploy-mode client. This will force the
driver to run on the client (i.e., workspace), so that you will see
the output of println. Otherwise, the driver will run on
an arbitrary cluster node, making stdout not directly visible.
Please follow these instructions carefully!
Make sure your repo has the following items:
bigdata2016w/assignment5.md.bigdata2016w/assignment5-Q5-small.pdf
and bigdata2016w/assignment5-Q5-large.pdf that contains
the graphs for Q5 on the TPC-H-0.1-TXT
and TPC-H-10-TXT datasets, respectively. If you cannot
easily generate PDFs, the files should be some easily-viewable format,
e.g., png, gif, etc.ca.uwaterloo.cs.bigdata2016w.lintool.assignment5. There
should be at the minimum seven classes (Q1-Q7), but you may include
helper classes as you see fit.Make sure your implementation runs in the Linux student CS
environment on TPC-H-0.1-TXT, and on the Alitscale
cluster on the TPC-H-10-TXT data.
Specifically, we will clone your repo and use the below check scripts:
check_assignment5_public_linux.py
in the Linux Student CS environment.check_assignment5_public_altiscale.py
on the Altiscale cluster.When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", we would recommend that you verify everything above works by performing a clean clone of your repo and run the public check scripts.
That's it!
The entire assignment is worth 100 points:
A working implementation means that your code gives the right
output according to our private check scripts, which will
contain --date parameters that are unknown to you (but
will nevertheless conform to our specifications above).
In this assignment, you will build a spam classifier trained using stochastic gradient descent in Spark, replicating the work described in Efficient and Effective Spam Filtering and Re-ranking for Large Web Datasets by Cormack, Smucker, and Clarke. We will draw your attention to specific sections of the paper that are directly pertinent to the assignment, but you should read the entire paper for background.
First let's grab the training and test data:
wget https://www.student.cs.uwaterloo.ca/~cs489/spam/spam.train.group_x.txt.bz2 wget https://www.student.cs.uwaterloo.ca/~cs489/spam/spam.train.group_y.txt.bz2 wget https://www.student.cs.uwaterloo.ca/~cs489/spam/spam.train.britney.txt.bz2 wget https://www.student.cs.uwaterloo.ca/~cs489/spam/spam.test.qrels.txt.bz2
The sizes of the above files are 5.5 MB, 6.6 MB, 248 MB, and 303 MB, respectively. After you've downloaded the data, unpack:
bunzip2 spam.train.group_x.txt.bz2 bunzip2 spam.train.group_y.txt.bz2 bunzip2 spam.train.britney.txt.bz2 bunzip2 spam.test.qrels.txt.bz2
Verify the unpacked data:
| File | MD5 | Size |
spam.train.group_x.txt | d6897ed8319c71604b1278b660a479b6 | 25 MB |
spam.train.group_y.txt | 4d103821fdf369be526347b503655da5 | 20 MB |
spam.train.britney.txt | b52d54caa20325413491591f034b5e7b | 766 MB |
spam.test.qrels.txt | df1d26476ec41fec625bc2eb9969875c | 1.1 GB |
Next, download the two files you'll need for evaluating the output of the spam classifier (links below):
Compile the C program:
gcc -O2 -o compute_spam_metrics compute_spam_metrics.c -lm
You might get some warnings but don't worry—the code should
compile fine. The actual evaluation script spam_eval.sh
(and spam_eval_hdfs.sh)
calls compute_spam_metrics, so make sure they're in the
same directory.
Note on local vs. Altiscale: for this assignment, your code must (eventually) work in Altiscale, but feel free to develop locally or in the Linux Student CS environment. The instructions below are written for running locally, but in a separate section later we will cover details specific to Altiscale.
In this assignment, we'll take you through building spam classifiers of increasing complexity, but let's start with a basic implementation using stochastic gradient descent. Build the spam classifier in exactly the way we describe below, because later parts of the assignment will depend on the setup.
First, let's write the classifier trainer. The classifier trainer takes all the training instances, runs stochastic gradient descent, and produces a model as output.
Look at the Cormack, Smucker, and Clarke paper: the entire algorithm is literally 34 lines of C, shown in Figure 2 on page 10. The stochastic gradient descent update equations are in equations (11) and (12) on page 11. We actually made things even simpler for you: the features used in the spam classifier are hashed byte 4-grams (thus, integers)—we've pre-computed the features for you.
Take a look at spam.train.group_x.txt. The first line
begins as follows:
clueweb09-en0094-20-13546 spam 387908 697162 426572 161118 688171 ...
In the file, each training instance is on a line. Each line begins with a document id, the string "spam" or "ham" (the label), and a list of integers (the features).
Therefore, your spam classifier will look something like this:
// w is the weight vector (make sure the variable is within scope)
val w = Map[Int, Double]()
// Scores a document based on its list of features.
def spamminess(features: Array[Int]) : Double = {
var score = 0d
features.foreach(f => if (w.contains(f)) score += w(f))
score
}
// This is the main learner:
val delta = 0.002
// For each instance...
val isSpam = ... // label
val features = ... // feature vector of the training instance
// Update the weights as follows:
val score = spamminess(features)
val prob = 1.0 / (1 + exp(-score))
features.foreach(f => {
if (w.contains(f)) {
w(f) += (isSpam - prob) * delta
} else {
w(f) = (isSpam - prob) * delta
}
})
We've given you the code fragment for the learner above as a starting point—it's your job to understand exactly how it works and turn it into a complete classifier trainer in Spark.
For the structure of the Spark trainer program, take a look at slide 14 in the Week 8, part 2 deck. We're going to build the configuration shown there (even though the slide says MapReduce, we're implementing it in Spark). Specifically, we're going run a single reducer to make sure we pump all the training instances through a single learner on the reducer end. The overall structure of your program is going to look something like this:
val textFile = sc.textFile("/path/to/training/data")
val trained = textFile.map(line =>{
// Parse input
// ..
(0, (docid, isSpam, features))
}).groupByKey(1)
// Then run the trainer...
trained.saveAsTextFile(...)
Note the mappers are basically just parsing the feature vectors and
pushing them over to the reducer side for additional processing. We
emit "0" as a "dummy key" to make sure all the training instances get
collected at the reducer end via groupByKey()... after
which you run the trainer (which applies the SGD updates, per
above). Of course, it's your job to figure out how to connect the
pieces together. This is the crux of the assignment.
Putting everything together, you will write a trainer program
called TrainSpamClassifier that we will execute in the
following manner:
spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.TrainSpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input spam.train.group_x.txt --model cs489-2016w-lintool-a6-model-group_x
The --input option specifies the input training
instances (from above); the --model option specifies the
output directory where the model goes. Inside the model
directory cs489-2016w-lintool-a6-model-group_x, there
should be a single file, part-00000, that contains the
trained model. The trained model should be a sequence of tuples, one
on each line; each tuple should contain a feature and its weight (a
double value). Something like:
$ head -5 cs489-2016w-lintool-a6-model-group_x/part-00000 (547993,2.019484093190069E-4) (577107,5.255371091500805E-5) (12572,-4.40967560913553E-4) (270898,-0.001340150007664197) (946531,2.560528666942676E-4)
Next, you will write another Spark program
named ApplySpamClassifier that will apply the trained spam
classifier to the test instances. That is, the program will read in
each input instance, compute the spamminess score (from above), and
make a prediction: if the spamminess score is above 0, classify the
document as spam; otherwise, classify the document as ham.
We will run the program in the following manner:
spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.ApplySpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input spam.test.qrels.txt \ --output cs489-2016w-lintool-a6-test-group_x --model cs489-2016w-lintool-a6-model-group_x
The --input option specifies the input test instances;
the --model option specifies the classifier model; and
the --output option specifies the output directory. The
test data is organized in exactly the same way as the training data.
The output of ApplySpamClassifier should be organized as
follows:
$ cat cs489-2016w-lintool-a6-test-group_x/* | sort | head -5 (clueweb09-en0000-00-00142,spam,2.601624279252943,spam) (clueweb09-en0000-00-01005,ham,2.5654162439491004,spam) (clueweb09-en0000-00-01382,ham,2.5893946346394188,spam) (clueweb09-en0000-00-01383,ham,2.6190102258752614,spam) (clueweb09-en0000-00-03449,ham,1.500142758578532,spam)
The first field in each tuple is the document id and the second field is the test label. These are just copied from the test data. The third field is the spamminess score, and the fourth field is the classifier's prediction.
Important: It is absolutely critical that your classifier does not use the label in the test data when making its predictions. The only reason the label is included in the output is to facilitate evaluation (see below).
Finally, you can evaluate your results:
$ ./spam_eval.sh cs489-2016w-lintool-a6-test-group_x 1-ROCA%: 17.25
The eval script prints the evaluation metric, which is the area under the receiver operating characteristic (ROC) curve. This is a common way to characterize classifier error. The lower this score, the better.
If you've done everything correctly up until now, you should be able to replicate the above results.
You should then be able to train on the group_y training set:
spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.TrainSpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input spam.train.group_y.txt --model cs489-2016w-lintool-a6-model-group_y
And make predictions:
spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.ApplySpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input spam.test.qrels.txt \ --output cs489-2016w-lintool-a6-test-group_y --model cs489-2016w-lintool-a6-model-group_y
And evaluate:
$ ./spam_eval.sh cs489-2016w-lintool-a6-test-group_y 1-ROCA%: 12.82
Finally, train on the britney training set:
spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.TrainSpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input spam.train.britney.txt --model cs489-2016w-lintool-a6-model-britney
And make predictions:
spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.ApplySpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input spam.test.qrels.txt \ --output cs489-2016w-lintool-a6-test-britney --model cs489-2016w-lintool-a6-model-britney
And evaluate:
$ ./spam_eval.sh cs489-2016w-lintool-a6-test-britney 1-ROCA%: 16.46
There may be some non-determinism in running over
the britney dataset, so you might get something slightly
different.
Here's a placeholder for question 1 that you're going to answer below (see Altiscale section).
Next, let's build an ensemble classifier. Start by gathering all the models from each of the individual classifiers into a common directory:
mkdir cs489-2016w-lintool-a6-model-fusion cp cs489-2016w-lintool-a6-model-group_x/part-00000 cs489-2016w-lintool-a6-model-fusion/part-00000 cp cs489-2016w-lintool-a6-model-group_y/part-00000 cs489-2016w-lintool-a6-model-fusion/part-00001 cp cs489-2016w-lintool-a6-model-britney/part-00000 cs489-2016w-lintool-a6-model-fusion/part-00002
With these three separate classifiers, implement two different ensemble techniques:
Write a program ApplyEnsembleSpamClassifier that we
will execute in the following manner:
spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.ApplyEnsembleSpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input spam.test.qrels.txt \ --output cs489-2016w-lintool-a6-test-fusion-average --model cs489-2016w-lintool-a6-model-fusion --method average
The --input option specifies the input test instances.
The --model option specifies the base directory of all
the classifier models; in this directory your program should expect
each individual model in a part-XXXXX file; it's okay to
hard code the part files for convenience. The --output
option specifies the output directory. Finally,
the --method option specifies the ensemble technique,
either "average" or "vote" per above.
Your prediction program needs to load all three models, apply the specified ensemble technique, and make predictions. Hint: Spark broadcast variables are helpful in this implementation.
The output format of the predictions should be the same as the
output of the ApplySpamClassifier program. You should be
able to evaluate with spam_eval.sh in the same way. Go
ahead and predict with the two ensemble techniques and evaluate the
predictions. Note that ensemble techniques can sometimes improve on
the best classifier; sometimes not.
Here's a placeholder for questions 2 and 3 that you're going to answer below (see Altiscale section).
How does the ensemble compare to just concatenating all the training data together and training a single classifier? Let's find out:
cat spam.train.group_x.txt spam.train.group_y.txt spam.train.britney.txt > spam.train.all.txt
Now train on this larger test set, predict, and evaluate.
Here's a placeholder for question 4 that you're going to answer below (see Altiscale section).
In class, we talked about how a model trained using stochastic gradient descent is dependent on the order in which the training instances are presented to the trainer. Let's explore this effect.
Modify the TrainSpamClassifier to implement a new
option --shuffle. With this option, the program will
randomly shuffle the training instances before running the
trainer:
spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.TrainSpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input spam.train.britney.txt --model cs489-2016w-lintool-a6-model-britney-shuffle --shuffle
You must shuffle the data using Spark. The way to accomplish this in Spark is to generate a random number for each instance and then sort the instances by the value. That is, you cannot simply read all the training instances into memory in the driver, shuffle, and then parallelize.
Obviously, the addition of the --shuffle option should
not break existing functionality; that is, without the option, the
program should behave exactly as before.
Note that in this case we're working with the britney
data because the two other datasets have very few
examples—random shuffles can lead to weird idiosyncratic
effects.
You should be able to evaluate the newly trained model in exactly the same way as above. If you are getting a wildly different 1-ROCA% scores each time, you're doing something wrong.
Here's a placeholder for question 5 that you're going to answer below (see Altiscale section).
You are free to develop locally on your own machine or in the Linux Student CS environment (and in fact, the instructions above assume so), but you must make sure that your code runs in Altiscale also. This is just to verify that your Spark programs will work in a distributed environment, and that you are not inadvertently taking advantage of some local feature.
All training and test data are located
in /shared/cs489/data/ on HDFS. Note that
spam.train.all.txt has already been prepared for you in
that directory also.
For example, training, predicting, and evaluating on
the group_x dataset in Altiscale:
my-spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.TrainSpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input /shared/cs489/data/spam.train.group_x.txt \ --model cs489-2016w-lintool-a6-model-group_x my-spark-submit --driver-memory 2g --class ca.uwaterloo.cs.bigdata2016w.lintool.assignment6.ApplySpamClassifier \ target/bigdata2016w-0.1.0-SNAPSHOT.jar --input /shared/cs489/data/spam.test.qrels.txt \ --output cs489-2016w-lintool-a6-test-group_x --model cs489-2016w-lintool-a6-model-group_x ./spam_eval_hdfs.sh cs489-2016w-lintool-a6-test-group_x
The major differences are:
my-spark-submit script for launching Spark programs.spam_eval_hdfs.sh for the evaluation script.Refer back to the placeholders above and answer the following questions, running your code on the Altiscale cluster:
Question 1: For each individual classifiers trained
on group_x, group_y,
and britney, what are the 1-ROCA% scores? You should be
able to replicate our results
on group_x, group_y, but there may be some
non-determinism for britney, which is why we want you to
report the figures.
Question 2: What is the 1-ROCA% score of the score averaging technique in the 3-classifier ensemble?
Question 3: What is the 1-ROCA% score of the voting technique in the 3-classifier ensemble?
Question 4: What is the 1-ROCA% score of a single classifier trained on all available training data concatenated together?
Question 5: Run the shuffle trainer 10 times on
the britney dataset, predict and evaluate the classifier
on the test data each time. Report the 1-ROCA% score in each of the
ten trials and compute the overall average.
Please follow these instructions carefully!
Make sure your repo has the following items:
bigdata2016w/assignment6.md.ca.uwaterloo.cs.bigdata2016w.lintool.assignment6. At the minimum, you should have
TrainSpamClassifier, ApplySpamClassifier,
and ApplyEnsembleSpamClassifier. Feel free to include helper code also.Make sure your implementation runs on the Altiscale cluster. The following check script is provided for you (check the source for the relevant flags):
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", we would recommend that you verify everything above works by performing a clean clone of your repo and run the public check scripts.
That's it!
The entire assignment is worth 60 points:
TrainSpamClassifier is worth 15 points.ApplySpamClassifier is
worth 5 points.ApplyEnsembleSpamClassifier is worth 6 points.--shuffle option
in TrainSpamClassifier is worth 5 points.In this assignment you'll revisit the inverted indexing and boolean
retrieval program in assignment 3. In
assignment 3, your indexer program wrote postings to HDFS
in MapFiles and your boolean retrieval program read
postings from those MapFiles. In this assignment, you'll
write postings to and read postings from HBase instead. In other
words, the program logic should not change, except for the backend
storage that you are using. This assignment is to be completed using
MapReduce in Java.
Because HBase requires additional daemon processes to be installed and configured properly, this assignment must be completed in the Altiscale environment. That is, do not use the Linux Student CS environment for this assignment.
To start, take a look at HBaseWordCount in Bespin,
which is in the
package io.bespin.java.mapreduce.wordcount. Make sure you
pull the repo to grab the latest version of the code.
The HBaseWordCount program is like the basic word count
demo, except that it stores the output in an HBase table. That is, the
reducer output is directly written to an HBase table: the word serves
as the row key, "c" is the column family, "count" is the column
qualifier, and the value is the actual count.
The HBaseWordCountFetch program in the same package
illustrates how you can fetch these counts out of HBase and shows you
how to use the basic HBase "get" API.
Study these two programs to make sure you understand how they work. The two sample program should give you a good introduction to the HBase APIs. A free online HBase book is a good source of additional details.
Make sure you can run both
programs. Running HBaseWordCount:
hadoop jar target/bespin-0.1.0-SNAPSHOT.jar io.bespin.java.mapreduce.wordcount.HBaseWordCount \ -config /home/hbase-0.98.16-hadoop2/conf/hbase-site.xml \ -input /shared/cs489/data/Shakespeare.txt -table lintool-wc-shakes -reducers 5
Use the -config option to specify the HBase config
file: point to a version on the Altiscale workspace that we've
prepared for you. This config file tells the program how to connect to
the HBase cluster. Use the -table option to name the
table you're inserting the word counts into. The other options should
be straightforward to understand.
Note: Since HBase is a shared resource across the cluster, please make your tables unique by using your username as part of the table name, per above.
You should then be able to fetch the word counts from HBase:
hadoop jar target/bespin-0.1.0-SNAPSHOT.jar io.bespin.java.mapreduce.wordcount.HBaseWordCountFetch \ -config /home/hbase-0.98.16-hadoop2/conf/hbase-site.xml \ -table lintool-wc-shakes -term love
If everything works, you'll discover that the term "love" appears 2053 times in the Shakespeare collection.
Next, you should try the same word count demo on the larger sample
wiki collection on HDFS
at /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt.
Now it's time to write some code! Following past procedures,
everything should go into the package namespace
ca.uwaterloo.cs.bigdata2016w.lintool.assignment7 (obviously, replace
lintool with your actual GitHub username. Note we're back
to coding in Java for this assignment.
Before you begin, you'll need to pull in the HBase-related
artifacts; otherwise, your code will not compile. Add the following
lines in the dependencies block of your pom.xml
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.98.16-hadoop2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>0.98.16-hadoop2</version>
</dependency>
You will write two programs, BuildInvertedIndexHBase
and BooleanRetrievalHBase. These are the counterparts of
the programs you wrote in assignment 3 (and the original Bespin
demos); feel free to use your code there as a starting point. Note
that you don't need to worry about index compression for this
assignment!
The BuildInvertedIndexHBase program is the HBase
version of BuildInvertedIndex from the Bespin
demo. Instead of writing the index to HDFS, you will write the index
to an HBase table. Use the following table structure: the term will be
the row key. Your table will have a single column family called
"p". In the column family, each document id will be a column
qualifier. The value will be the term frequency.
The BooleanRetrievalHBase program is the HBase version
of BooleanRetrieval from the Bespin demo. This program
should read postings from HBase. Note that the only thing you need to
change is the method fetchDocumentSet: instead of reading
from the MapFile, you'll read from HBase.
We advise that you begin with the Shakespeare dataset. You should be able to build the HBase index with the following command:
hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment7.BuildInvertedIndexHBase \ -config /home/hbase-0.98.16-hadoop2/conf/hbase-site.xml \ -input /shared/cs489/data/Shakespeare.txt \ -table cs489-2016w-lintool-a7-index-shakespeare -reducers 4
And run a query as follows:
hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment7.BooleanRetrievalHBase \ -config /home/hbase-0.98.16-hadoop2/conf/hbase-site.xml \ -table cs489-2016w-lintool-a7-index-shakespeare\ -collection /shared/cs489/data/Shakespeare.txt \ -query "outrageous fortune AND"
After you've verified that everything works on the smaller Shakespeare collection, move on to the sample Wikipedia collection. Index as follows:
hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment7.BuildInvertedIndexHBase \ -config /home/hbase-0.98.16-hadoop2/conf/hbase-site.xml \ -input /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt \ -table cs489-2016w-lintool-a7-index-wiki -reducers 5
And run a query as follows:
hadoop jar target/bigdata2016w-0.1.0-SNAPSHOT.jar \ ca.uwaterloo.cs.bigdata2016w.lintool.assignment7.BooleanRetrievalHBase \ -config /home/hbase-0.98.16-hadoop2/conf/hbase-site.xml \ -collection /shared/cs489/data/enwiki-20151201-pages-articles-0.1sample.txt \ -table cs489-2016w-lintool-a7-index-wiki \ -query "waterloo stanford OR cheriton AND"
You should verify that all the sample queries (from assignment 3) on both collections work.
Please follow these instructions carefully!
Make sure your repo has the following items:
bigdata2016w/assignment7.md. Otherwise, please create
an empty file—following previous assignments, this is where the
grade with go.ca.uwaterloo.cs.bigdata2016w.lintool.assignment7. At the minimum, you should have
BuildInvertedIndexHBase
and BooleanRetrievalHBase. Feel free to include helper
code also.The following check script is provided for you:
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", we would recommend that you verify everything above works by performing a clean clone of your repo and run the public check scripts.
That's it!
The entire assignment is worth 30 points:
BuildInvertedIndexHBase is
worth 10 points; the implementation
to BooleanRetrievalHBase is worth 5 points.The final project is a requirement only for graduate students taking CS 698.
The topic of the final project can be on anything you wish in the space of big data. Anything reasonably related to topics that we covered in the course is within scope. For reference, there are three types of projects you might consider:
You may work in groups of up to three, or you can also work by yourself if you wish. The amount of effort devoted to the project should be proportional to the number of people in the team. We would expect a level of effort comparable to two assignments per person.
When you are ready, send the
instructors uwaterloo-bigdata-2016w-staff@googlegroups.com
an email describing what you'd like to work on. We will provide you
feedback on appropriateness, scope, etc.
In terms of resources, you are welcome to use the Altiscale cluster. Note that we expect your project to be more than a "toy". To calibrate what we mean by "toy", consider the assignments throughout the course: they have a "run on local" part and "run on Altiscale" part. The first part is "toy"; the Altiscale part would not be. If you're planning to work with a framework that doesn't run on Altiscale, you're responsible for finding your own hardware resources.
The deliverable for the final project is a report. Use the ACM Templates. The contents of the report will of course vary by the topic, but we would expect the following sections:
Once again, length would vary, but 6 pages (in the ACM Template) seems about right.