Assignments
Data-Intensive Distributed Computing (Winter 2018)
Note that there separate sets of assignments for CS 451/651 and CS 431/631. Make sure you work on the correct asssignments!
Assignment 1: Counting in MapReduce due 2:30pm January 23
By now, you should already be familiar with the Hadoop execution
environment (e.g., submitting jobs) and using Maven to organize your
assignments. You will be working in the same repo as before, except
that everything should go into the package namespace
ca.uwaterloo.cs451.a1.
Note that the point of assignment 0 was to familiarize you with GitHub and the Hadoop development environment. Starting this assignment, excuses along the lines of "I couldn't get my repo set up properly", "I couldn't figure out how to push my assignment to GitHub", etc. will not be accepted. It is your responsibility to sort through any mechanics issue you have.
Before starting this assignment, it is highly recommended that you look at the implementations of bigram relative frequency and co-occurrence matrix computation in Bespin.
In this assignment you'll be computing pointwise mutual information, which is a function of two events x and y:
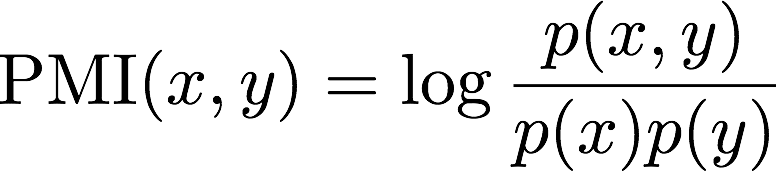
The larger the magnitude of PMI for x and y is, the more information you know about the probability of seeing y having just seen x (and vice-versa, since PMI is symmetrical). If seeing x gives you no information about seeing y, then x and y are independent and the PMI is zero.
Write two separate implementations (more details below) that
computes the PMI of words in the
data/Shakespeare.txt collection that's used in the Bespin
demos and the previous assignment. Your implementation should be in
Java. To be more specific, the event we're after is x occurring
on a line in the file (the denominator in the above equation)
or x and y co-occurring on a line (the numerator in the
above equation). That is, if a line contains "A B C", then the
co-occurring pairs are:
- (A, B)
- (A, C)
- (B, A)
- (B, C)
- (C, A)
- (C, B)
If the line contains "A A B C", the co-occurring pairs are still the same as above; same if the line contains "A B C A B C"; or any combinations of A, B, and C in any order.
A few additional specifications:
- In addition to PMI, it's also important to know how many times the
pair actually co-occurs, so you'll include this information in the
output (format explained below). To reduce the number of spurious
pairs, we want to be able to specify a command-line
option
-thresholdto indicate the threshold of co-occurrence. For example, if we specify-threshold 10, then we are only interested in pairs of words that co-occur in ten or more lines. - To reduce the computational complexity of the problem (since we're generating intermediate data that is quadratic with respect to the input), we are only going to consider up to only the first 40 words on each line (using the definition of "word" below).
- Just so everyone's answer is consistent, please use log base 10.
- Use the same definition of "word" as in the word count demo.
To ensure consistent tokenization, use the Tokenizer class provided in Bespin that you've used for assignment 0.
You will build two versions of the program (put both in
package ca.uwaterloo.cs451.a1):
- A "pairs" implementation. The implementation must use
combiners. Name this implementation
PairsPMI. In the final output, the key should be a co-occurring pair, e.g., (A, B), and the value should be a pair (PMI, count) denoting its PMI and co-occurrence count. - A "stripes" implementation. The implementation must use
combiners. Name this implementation
StripesPMI. In the final output, the key should be a word (e.g., A), and the value should be a map, where each of the keys is a co-occurring word (e.g., B), and the value is a pair (PMI, count) denoting its PMI and co-occurrence count.
Since PMI is symmetrical, PMI(x, y) = PMI(y, x). However, it's
actually easier in your implementation to compute both values, so
don't worry about duplicates. Also, use TextOutputFormat
so the results of your program are human readable.
Make sure that the pairs implementation and the stripes implementation give the same answers!
Answer the following questions:
Question 1. (6 points) Briefly describe in prose your solution, both the pairs and stripes implementation. For example: how many MapReduce jobs? What are the input records? What are the intermediate key-value pairs? What are the final output records? A paragraph for each implementation is about the expected length.
Question 2. (2 points) What is the running time of the complete pairs
implementation? What is the running time of the complete stripes
implementation? (Tell me where you ran these experiments,
e.g., linux.student.cs.uwaterloo.ca or your own
laptop.)
Question 3. (2 points) Now disable all combiners. What is the running
time of the complete pairs implementation now? What is the running
time of the complete stripes implementation? (Tell me where you ran
these experiments, e.g., linux.student.cs.uwaterloo.ca or
your own laptop.)
Question 4. (3 points) How many distinct PMI pairs did you
extract? Use -threshold 10.
Question 5. (6 points) What's the pair (x, y) (or pairs if
there are ties) with the highest PMI? Use -threshold
10. Similarly, what's the pair with the lowest (negative) PMI?
Use the same threshold. Write a sentence or two to explain these
results.
Question 6. (6 points) What are the three words that have
the highest PMI with "tears" and "death"? -threshold
10. And what are the PMI values?
Make sure that your code runs in the Linux Student CS environment (even if you do development on your own machine), which is where we will be doing the grading. "But it runs on my laptop!" will not be accepted as an excuse if we can't get your code to run.
Note that you can compute the answer to questions 4—6 however you wish: a helper Java program, a Python script, command-line one-liner, etc.
Running on the Altiscale cluster
Now, on the Altiscale cluster, run your pairs and stripes
implementation on the sample Wikipedia collection stored on HDFS
at /shared/uwaterloo/cs451/data/simplewiki-20161220-sentences.txt. This
is a dump
of "simple"
Wikipedia that has been tokenized into sentences, one per line. As
with the Shakespeare collection, we care about co-occurrence on a line
(which is a sentence in this case).
Make sure your code runs on this larger dataset. Assuming that there aren't many competing jobs on the cluster, your programs should not take more than 20 minutes to run. For reference, on an idle cluster, the reference pairs implementation takes around 6 minutes to run and the reference stripes implementation takes around 4 minutes to run.
If your job is taking much longer than that or if it doesn't look your job is making obvious progress, then please kill it so it doesn't waste resources and slow other people's jobs down. To kill your job, first find its application id in the RM webapp, then issue:
$ yarn application -kill application_xxxxxxxxxxxxx_xxxx
Obviously, if the cluster is really busy or if there's a long list of queued jobs, your job will take longer, so use your judgement here. The only point is: be nice. It's a shared resource, and let's not let runaway jobs slow everyone down.
One final detail, set your MapReduce job parameters as follows:
job.getConfiguration().setInt("mapred.max.split.size", 1024 * 1024 * 32);
job.getConfiguration().set("mapreduce.map.memory.mb", "3072");
job.getConfiguration().set("mapreduce.map.java.opts", "-Xmx3072m");
job.getConfiguration().set("mapreduce.reduce.memory.mb", "3072");
job.getConfiguration().set("mapreduce.reduce.java.opts", "-Xmx3072m");
What the last four options do is fairly obvious. The first sets the maximum split size to be 32 MB. What effect does that have? (Hint, consider the physical execution of MapReduce programs we discussed in class)
Question 7. (5 points) In the Wikipedia dataset, what are
the five words that have the highest PMI with "hockey"? And how many
times do these words co-occur? Use -threshold 50.
Question 8. (5 points) Same as above, but with the word "data".
It's worth noting again: the Altiscale cluster is a shared resource, and how fast your jobs complete will depend on how busy it is. You're advised to begin the assignment early as to avoid long job queues. "I wasn't able to complete the assignment because there were too many jobs running on the cluster" will not be accepted as an excuse if your assignment is late.
Turning in the Assignment
Please follow these instructions carefully!
Make sure your repo has the following items:
- Similar to assignment 0, the answers to the questions go
in
bigdata2018w/assignment1.md. - The pairs and stripes implementation should be in
package
ca.uwaterloo.cs451.a1.
When grading, we will pull your repo and build your code:
$ mvn clean package
Your code should build successfully. We are then going to check your code (both the pairs and stripes implementations).
We're going to run your code on the Linux student CS environment as follows (we will make sure the collection is there):
$ hadoop jar target/assignments-1.0.jar ca.uwaterloo.cs451.a1.PairsPMI \ -input data/Shakespeare.txt -output cs451-lintool-a1-shakespeare-pairs \ -reducers 5 -threshold 10 $ hadoop jar target/assignments-1.0.jar ca.uwaterloo.cs451.a1.StripesPMI \ -input data/Shakespeare.txt -output cs451-lintool-a1-shakespeare-stripes \ -reducers 5 -threshold 10
Make sure that your code runs in the Linux Student CS environment (even if you do development on your own machine), which is where we will be doing the grading. "But it runs on my laptop!" will not be accepted as an excuse if we can't get your code to run.
You can run the above instructions using
check_assignment1_public_linux.py,
with something like:
$ wget http://lintool.github.io/bigdata-2018w/assignments/check_assignment1_public_linux.py $ chmod +x check_assignment1_public_linux.py $ ./check_assignment1_public_linux.py lintool
We're going to run your code on the Altiscale cluster as follows:
$ hadoop jar target/assignments-1.0.jar ca.uwaterloo.cs451.a1.PairsPMI \ -input /shared/uwaterloo/cs451/data/simplewiki-20161220-sentences.txt -output cs451-lintool-a1-wiki-pairs \ -reducers 5 -threshold 50 $ hadoop jar target/assignments-1.0.jar ca.uwaterloo.cs451.a1.StripesPMI \ -input /shared/uwaterloo/cs451/data/simplewiki-20161220-sentences.txt -output cs451-lintool-a1-wiki-stripes \ -reducers 5 -threshold 50
You can run the above instructions using
check_assignment1_public_altiscale.py,
with something like:
$ wget http://lintool.github.io/bigdata-2018w/assignments/check_assignment1_public_altiscale.py $ chmod +x check_assignment1_public_altiscale.py $ ./check_assignment1_public_altiscale.py lintool
Important: Make sure that your code accepts the command-line parameters above! That is, make sure the check scripts work!
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", verify everything above works by performing a clean clone of your repo and going through the steps above.
That's it! There's no need to send us anything—we already know your username from assignment 0. Note that everything should be committed and pushed to origin before the deadline.
Hints
- Did you take a look at the implementations of bigram relative frequency and co-occurrence matrix computation in Bespin?
- Your solution will likely require more than one MapReduce job.
- You may have to load in "side data"?
- See this example for how to pass in a command-line argument.
- Counters may be useful for... well, counting.
- My lintools-datatypes
package has
Writabledatatypes that you might find useful. (Feel free to use, but assignment can be completed without it.)
Grading
This assignment is worth a total of 70 points, broken down as follows:
- The questions above are worth a total of 35 points.
- Getting your code to compile and successfully run is worth
another 20 points (5 points each for the pairs and stripes
implementation in the Linux student CS environment and on
Altiscale). We will make a minimal effort to fix trivial
issues with your code (e.g., a typo)—and deduct
points—but will not spend time debugging your code. It
is your responsibility to make sure your code runs: we have taken
care to specify exactly how we will run your code—if anything
is unclear, it is your responsibility to seek clarification. In
order to get a perfect score of 16 for this portion of the grade, we
should be able to run the two public check
scripts:
check_assignment1_public_linux.py(on Linux Student CS) ancheck_assignment1_public_altiscale.py(on Altiscale cluster) successfully without any errors. - Another 15 points is allotted to us verifying the output of your program in ways that we will not tell you. We're giving you the "public" versions of the check scripts; we'll run a "private" version to examine your output further (i.e., think blind test cases).