Data-Intensive Distributed Computing
CS 451/651 431/631 (Winter 2018)
Time: Tuesdays and Thursdays, 2:30-3:50pm
Location: RCH 307
Instructors: Jimmy Lin (CS 451/461) and Ken Salem (CS 431/631)
TAs: Youngbin Kim, Royal Sequiera, Zhucheng (Michael) Tu
Piazza: course link — use for general questions
Email: uwaterloo-bigdata-2018w-staff@googlegroups.com (will reach instructors and TAs) — use only for personal concerns
Over the past decade, we have seen the emergence of "big data": disruptive technologies that have transformed commerce, science, and many aspects of society. These developments are enabled by infrastructure that allows us to distribute computations across hundreds or even thousands of commodity servers. One important advance that has made all this possible is the development of abstractions for data-intensive computing that allow programmers to reason about computations at a massive scale, hiding low-level details such as synchronization, data movement, and fault tolerance.
What is this course about? This course provides an introduction to data-intensive distributed computing. Our focus is algorithm design and "thinking at scale": we will cover data mining and machine learning techniques as applied to text, graphs, and relational data. Most of the course will be taught in a combination of MapReduce and Spark, two representative dataflow abstractions for large-scale data analysis, although we will introduce alternative abstractions such as bulk-synchronous parallel and streaming models as well.
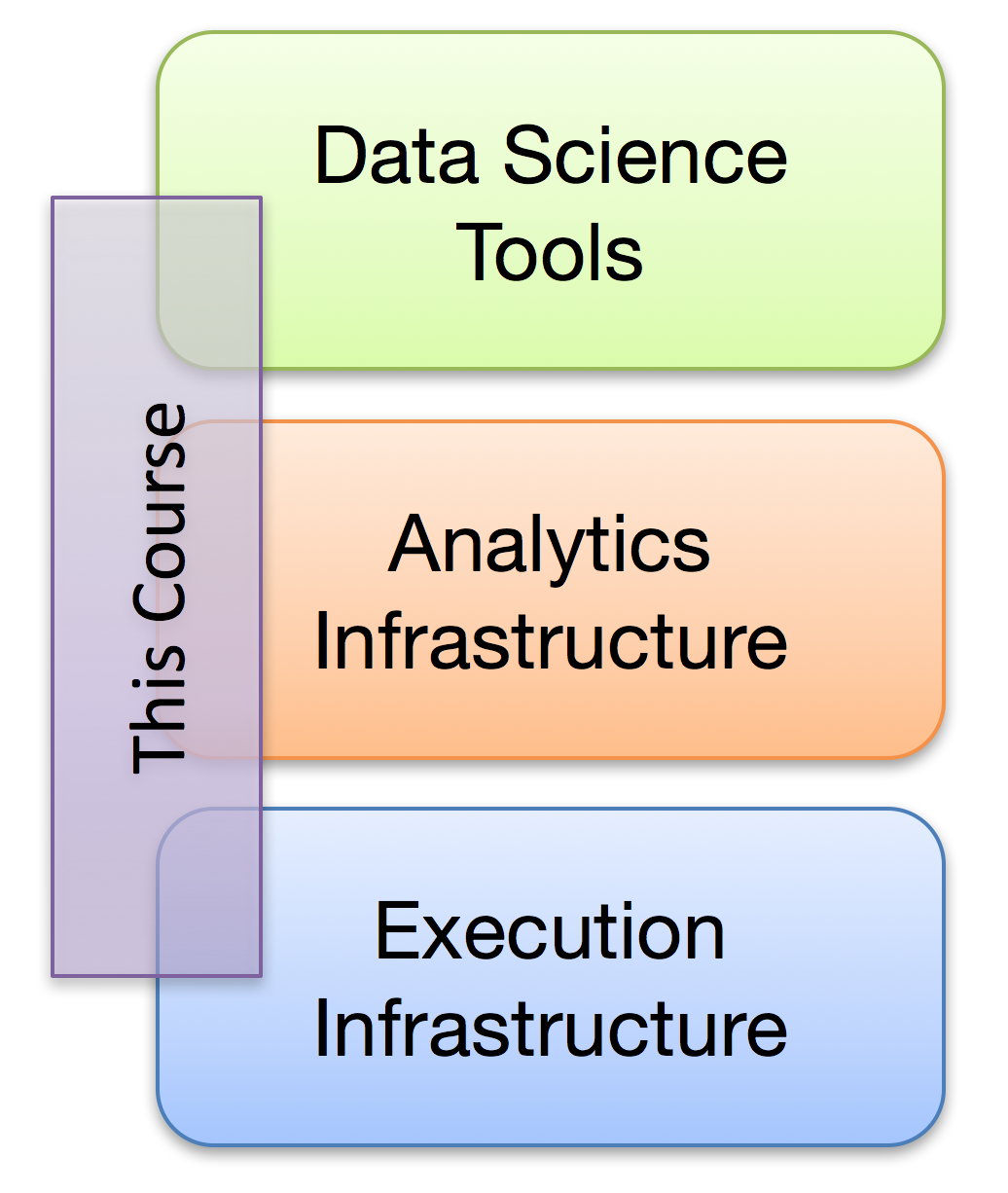
One might break down the "big data" stack in the manner shown on the right. At the bottom resides the execution infrastructure, which is responsible for coordinating computations across a cluster (examples include MapReduce and Spark). In the middle resides analytics infrastructure, which implements data mining and machine learning algorithms on top of the execution infrastructure (an example would be MLlib in Spark). At the top are the tools data scientists use to generate insights, built on top of the analytics infrastructure. This course focuses on the middle part — by the end of the course, you will be able to implement basic data mining and machine learning algorithms that can operate at scale. Of course, effective algorithm design requires understanding the execution infrastructure (below) and what the algorithms are used for (above), so we will cover the broader context as well.