Assignments Big Data Infrastructure (Spring 2015)
Assignment 0: Prelude due 6:00pm January 26
Note that this course requires you to have access to a reasonable recent computer with at least 4 GB memory and plenty of hard disk space.
Complete the word count tutorial in Cloud9, which is a Hadoop toolkit we're going to use throughout the course. The tutorial will take you through setting up Hadoop on your local machine and running Hadoop on the virtual machine. It'll also begin familiarizing you with GitHub.
Note: This assignment is not explicitly graded, except as part of Assignment 1.
Assignment 1: Warmup due 6:00pm February 2
Make sure you've completed the word count tutorial in Cloud9.
Sign up for a GitHub account. It is very important that you do so as soon as possible, because GitHub is the mechanism by which you will submit assignments. Once you've signed up for an account, go to this page to request an educational account.
Next, create a private repo
called bigdata-assignments. Here
is how you
create a repo on GitHub. For "Who has access to this repository?",
make sure you click "Only the people I specify". If you've
successfully gotten an educational account (per above), you should be
able to create private repos for free. Take some time to learn about
git if you've never used it before. There are plenty of good tutorials
online: do a simple web search and find one you like. If you've used
svn before, many of the concepts will be familiar, except that git
is far more powerful.
After you've learned about git, set aside the repo for now; you'll come back to it later.
In the single node virtual cluster in the word count tutorial, you should have already ran the word count demo with five reducers:
$ hadoop jar target/cloud9-X.Y.Z-fatjar.jar edu.umd.cloud9.example.simple.DemoWordCount \ -input bible+shakes.nopunc -output wc -numReducers 5
Answer the following questions (see instructions below for how to "turn in" these answers):
Question 1. What is the first term
in part-r-00000 and how many times does it appear?
Question 2. What is the third to last term
in part-r-00004 and how many times does it appear?
Question 3. How many unique terms are there? (Hint: read the counter values)
Time to write some code!
Per above, you should have a private GitHub repo called
bigdata-assignments/. Change into that directory. Once
inside, create a Maven project with the following command:
$ mvn archetype:create -DgroupId=edu.umd.YOUR_USERNAME -DartifactId=assignment1
For YOUR_USERNAME, please use your GitHub username
(not your UMD directory ID, not your email address, or anything
else...). In what follows below, I will use
jimmylin, but you should obviously substitute your
own. Once you've executed the above command you should be able
to cd
into bigdata-assignments/assignment1. In that directory,
you'll find a pom.xml file (which tells Maven how to
build your code); replace with this
one here (which is set up properly
for Hadoop), but inside this pom.xml, change the
following line and replace my username with yours.
<groupId>edu.umd.jimmylin</groupId>
Next,
copy Cloud9/src/main/java/edu/umd/cloud9/example/simple/DemoWordCount.java
into bigdata-assignments/assignment1/src/main/java/edu/umd/jimmylin/. Open
up this new version of DemoWordCount.java
in assignment1/ using a text editor and change the Java
package to edu.umd.jimmylin.
Now, in the bigdata-assignments/assignment1 base
directory, you should be able to run Maven to build your package:
$ mvn clean package
Once the build succeeds, you should be able to run the word count demo program in your own repository:
$ hadoop jar target/assignment1-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.DemoWordCount \ -input bible+shakes.nopunc -output wc -numReducers 5
The output should be exactly the same as the program above, but the difference here is that the code is now in a repository under your control. Congratulations, you've created your first functional Maven artifact!
Let's do a little bit of cleanup of the words. Modify the word
count demo (your newly-created version in assignment1/)
so that only words consisting entirely of letters are counted. To be
more specific, the word must match the following Java regular
expression:
word.matches("[A-Za-z]+")
Now run this modified word count, again with five reducers. Answer the following questions:
Question 4. What is the first term
in part-r-00000 and how many times does it appear?
Question 5. What is the third to last term
in part-r-00004 and how many times does it appear?
Question 6. How many unique terms are there?
Turning in the Assignment
Please follow these instructions carefully!
At this point, you should have a GitHub
repo bigdata-assignments, and inside the repo, you should
have a directory
called assignment1/. Under assignment1/, you
should already have the code for the modified word count example above
(i.e., questions 4, 5, 6). Commit all of this code and push to
GitHub.
Next, under assignment1/, create a file
called assignment1.md. In that file, put your answers to
the above questions 1 through 6. Use the Markdown annotation format:
here's
a simple
guide. Here's an online
editor that's also helpful.
Make sure you have committed everything and have pushed your repo back to origin. You can verify that it's there by logging into your GitHub account (in a web browser): your assignment should be viewable in the web interface.
Almost there! Add the user teachtool a collaborator to your repo so that I can check it out (under settings in the main web interface on your repo). Note: do not add my primary GitHub account lintool as a collaborator.
Finally, send me an email, to jimmylin@umd.edu with the subject line "Big Data Infrastructure Assignment #1". In the body of the email message, tell me what your GitHub username is so that I can link your repo to you. Also, in your email please tell me how long you spent doing the assignment, including everything (installing the VM, learning about git, working through the tutorial, etc.).
Grading
Here's how I am going to grade your assignment. I will clone your
repo, go into your assignment1/ directory, and build your
Maven artifact:
$ mvn clean package
I am then going to run your code:
$ hadoop jar target/assignment1-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.DemoWordCount \ -input bible+shakes.nopunc -output wc -numReducers 5
Once the code completes, I will verify its output. To make sure everything is in the proper place, you should do a fresh clone, i.e., clone your own repo, but in a different location, and run through these same steps. If it works for you, it'll work for me.
The purpose of this assignment is to familiarize you with the Hadoop development environment. You'll get a "pass" if you've successfully completed the assignment. I expect everyone to get a "pass".
Assignment 2: Counting due 6:00pm February 23
Begin by setting up your development environment. In your GitHub
repo bigdata-assignments/, create a Maven project with
the following command:
$ mvn archetype:create -DgroupId=edu.umd.YOUR_USERNAME -DartifactId=assignment2
For YOUR_USERNAME, please use your GitHub username
(not your UMD directory ID, not your email address, or anything
else...). In what follows below, I will use
jimmylin, but you should obviously substitute your
own. Once you've executed the above command, change directory
to bigdata-assignments/assignment2. In that directory,
replace pom.xml with this
version here (which is set up
properly for Hadoop). However, inside pom.xml, change the
following line and replace my username with yours.
<groupId>edu.umd.jimmylin</groupId>
Also, replace all instances of assignment1 with
assignment2.
The actual assignment begins with an optional but recommended component: complete the bigram counts exercise in Cloud9. The solution is already checked in the repo, so it won't be graded. Even if you decide not to write code for the exercise, take some time to sketch out what the solution would look like. The exercises are designed to help you learn: jumping directly to the solution defeats this purpose.
In this assignment you'll be computing pointwise mutual information, which is a function of two events x and y:
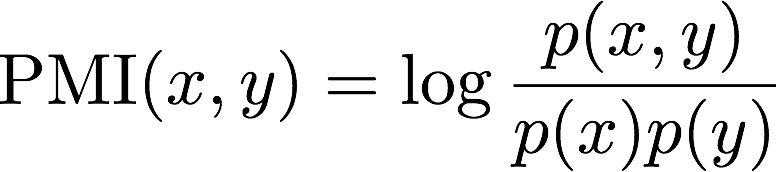
The larger the magnitude of PMI for x and y is, the more information you know about the probability of seeing y having just seen x (and vice-versa, since PMI is symmetrical). If seeing x gives you no information about seeing y, then x and y are independent and the PMI is zero.
To complete this assignment, you'll need to work with the UMIACS
cluster. In the beginning of the assignment you'll be working with the
toy bible+shakes.nopunc.gz corpus, but later you'll move
to a larger corpus (more below). You can start working on the UMIACS
cluster directly, or you can start on the Cloudera VM and move to the
UMIACS cluster later. It's your choice, but as we discussed in class,
debugging may be easier inside your Cloudera VM.
Write a program that computes the PMI of words in the
sample bible+shakes.nopunc.gz corpus. To be more
specific, the event we're after is x occurring on a line in the
file or x and y co-occurring on a line. That is, if a
line contains A, A, B; then there is only one instance of A and B
appearing together, not two. To reduce the number of spurious pairs,
we are only interested in pairs of words that co-occur in ten or more
lines. Use the same definition of "word" as in the word count demo:
whatever Java's StringTokenizer gives.
You will build two versions of the program (put both in
package edu.umd.YOUR_USERNAME):
- A "pairs" implementation. The implementation must use
combiners. Name this implementation
PairsPMI. - A "stripes" implementation. The implementation must use
combiners.
StripesPMI.
If you feel compelled (for extra credit), you are welcome to try out the "in-mapper combining" technique for both implementations.
Since PMI is symmetrical, PMI(x, y) = PMI(y, x). However, it's
actually easier in your implementation to compute both values, so
don't worry about duplicates. Also, use TextOutputFormat
so the results of your program are human readable.
Note: just so everyone's answer is consistent, please use log base 10.
Answer the following questions:
Question 0. Briefly describe in prose your solution, both the pairs and stripes implementation. For example: how many MapReduce jobs? What are the input records? What are the intermediate key-value pairs? What are the final output records? A paragraph for each implementation is about the expected length.
Question 1. What is the running time of the complete pairs implementation? What is the running time of the complete stripes implementation? (Did you run this in your VM or on the UMIACS cluster? Either is fine, but tell me which one.)
Question 2. Now disable all combiners. What is the running time of the complete pairs implementation now? What is the running time of the complete stripes implementation? (Did you run this in your VM or on the UMIACS cluster? Either is fine, but tell me which one.)
Question 3. How many distinct PMI pairs did you extract?
Question 4. What's the pair (x, y) with the highest PMI? Write a sentence or two to explain what it is and why it has such a high PMI.
Question 5. What are the three words that have the highest PMI with "cloud" and "love"? And what are the PMI values?
Note that you can compute the answer to questions 3—5 however you wish: a helper Java program, a Python script, command-line manipulation, etc.
Now, answer the same questions 1—5 for the following corpus, which is stored on HDFS on the UMAICS cluster:
/shared/simplewiki-20141222-pages-articles.txt
That file is 121 MB and contains the latest version of Simple English Wikipedia. Number the answers to these questions 6—10.
Note that it is possible to complete questions 1—5 on your Cloudera VM, but you must answer questions 6—10 on the UMIACS cluster. This is to ensure that your code "scales correctly".
Turning in the Assignment
Please follow these instructions carefully!
Make sure your repo has the following items:
- Similar to your first assignment, the answers to the questions go
in
bigdata-assignments/assignment2/assignment2.md. - The pairs and stripes implementation should be
in
bigdata-assignments/assignment2/src/. Of course, your repo may contain other Java code.
When grading, I will perform a clean clone of your repo, change
directory into bigdata-assignments/assignment2/ and build
your code:
$ mvn clean package
Your code should build successfully. I am then going to run your code (for the pairs and stripes implementations, respectively):
$ hadoop jar target/assignment2-1.0-SNAPSHOT-fatjar.jar edu.umd.YOUR_USERNAME.PairsPMI \ -input DATA -output output-pairs -numReducers 5 $ hadoop jar target/assignment2-1.0-SNAPSHOT-fatjar.jar edu.umd.YOUR_USERNAME.StripesPMI \ -input DATA -output output-stripes -numReducers 5
For DATA, I am either going to
use bible+shakes.nopunc
or simplewiki-20141222-pages-articles.txt (you can assume
that I'll supply the correct HDFS path). Note that I am going to check
the output and I expect the contents in the final output on HDFS to be
human readable.
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", I would recommend that you verify everything above works by performing a clean clone of your repo and going through the steps above.
That's it! There's no need to send me anything—I already know your username from the first assignment. Note that everything should be committed and pushed to origin before the deadline (before class on February 16). Git timestamps your commits and so I can tell if your assignment is late.
Hints
- Did you take a look at the bigram counts exercise?
- Your solution may require more than one MapReduce job.
- Recall from lecture techniques for loading in "side data"?
- Look in
edu.umd.cloud9.example.cooccurfor a reference implementation of the pairs and stripes techniques. - As disscussed in class,
my lintools-datatypes
package package has
Writabledatatypes that you might find useful.
Grading
The entire assignment is worth 40 points:
- Each of the questions 1 to 10 is worth 1 point, for a total of 10 points.
- The pairs implementation is worth 10 points and the stripes implementation is worth 10 points. The purpose of question 0 is to help me understand your implementation.
- Getting your code to run is worth 5 points for each implementation (i.e., 10 points total). That is, to earn all five points, I should be able to run your code (building and running), following exactly the procedure above. Therefore, if all the answers are correct and the implementation seems correct, but I cannot get your code to build and run, you will only get a score of 30/40.
Assignment 3: Inverted Indexing due 6:00pm March 2
Begin by setting up your development environment. The process is
exactly the same as in the previous assignment. In your GitHub
repo bigdata-assignments/, create a Maven project with
the following command:
$ mvn archetype:create -DgroupId=edu.umd.YOUR_USERNAME -DartifactId=assignment3
For YOUR_USERNAME, please use your GitHub
username. Once you've executed the above command, change directory
to bigdata-assignments/assignment3. In that directory,
replace pom.xml with this
version here (which is set up
properly for Hadoop). However, inside pom.xml, change the
following line and replace my username with yours.
<groupId>edu.umd.jimmylin</groupId>
Also, replace all instances of assignment1 with
assignment3.
This assignment begins with an optional but recommended component: complete the inverted indexing exercise and boolean retrieval exercise in Cloud9. The solution is already checked in the repo, so it won't be graded. However, the rest of the assignment builds from there. Even if you decide not to write code for those two exercises, take some time to sketch out what the solution would look like. The exercises are designed to help you learn: jumping directly to the solution defeats the purpose.
Starting from the inverted indexing baseline, modify the indexer code in the two following ways:
1. Index Compression. The index should be compressed using
VInts: see org.apache.hadoop.io.WritableUtils. You should
also use gap-compression techniques as appropriate.
2. Scalability. The baseline indexer implementation currently buffers and sorts postings in the reducer, which as we discussed in class is not a scalable solution. Address this scalability bottleneck using techniques we discussed in class and in the textbook.
Note: The major scalability issue is buffering uncompressed postings in memory. In your solution, you'll still end up buffering each postings list, but in compressed form (raw bytes, no additional object overhead). This is fine because if you use the right compression technique, the postings lists are quite small. As a data point, on a collection of 50 million web pages, 2GB heap is more than enough for a full positional index (and in this assignment you're not asked to store positional information in your postings).
To go into a bit more detail: in the reference implementation, the
final key type is PairOfWritables<IntWritable,
ArrayListWritable<PairOfInts>>. The most obvious idea
is to change that into something
like PairOfWritables<VIntWritable,
ArrayListWritable<PairOfVInts>>. This does not work!
The reason is that you will still be materializing each posting, i.e.,
all PairOfVInts objects in memory. This translates into a
Java object for every posting, which is wasteful in terms of memory
usage and will exhaust memory pretty quickly as you scale. In other
words, you're still buffering objects—just inside
the ArrayListWritable.
This new indexer should be
named BuildInvertedIndexCompressed. This new class should
be in the package edu.umd.YOUR_USERNAME. Make sure it
works on the bible+shakes.nopunc collection.
Modify BooleanRetrieval
so that it works with the new compressed indexes (on
the bible+shakes.nopunc collection). Name this new
class BooleanRetrievalCompressed. This new class should
be in the package edu.umd.YOUR_USERNAME and
give exactly the same output as the old version.
Next, make sure your BuildInvertedIndexCompressed
and BooleanRetrievalCompressed implementations work on
the larger collection on HDFS in the UMIACS cluster:
/shared/simplewiki-20141222-pages-articles.txt
Note that BooleanRetrievalCompressed has a number of
queries that are hard-coded in the main. For simplicity,
use those same queries on the simplewiki collection also.
Another note: the BooleanRetrieval reference
implementation prints out the entire line (i.e., "document") that
satisfies the query. For the bible+shakes.nopunc
collection, this is fine since the lines are short. However, in the
simplewiki collection, the lines (i.e., documents) are much longer, so
you should somehow truncate: either print out only the article title
or the first 80 characters, or something along those lines.
Answer the following questions:
Question 1. What is the size of your compressed index for bible+shakes.nopunc?
Question 2. What is the size of your compressed index for simplewiki-20141222-pages-articles.txt?
Question 3. Which articles in simplewiki-20141222-pages-articles.txt satisfy the following boolean queries?
outrageous AND fortune means AND deceit (white OR red ) AND rose AND pluck (unhappy OR outrageous OR (good AND your)) AND fortune
Note that I just want the article titles only (not the actual text).
Turning in the Assignment
Please follow these instructions carefully!
Make sure your repo has the following items:
- Similar to your second assignment, the answers to the questions go
in
bigdata-assignments/assignment3/assignment3.md. - Your code goes in
bigdata-assignments/assignment3/src/.
When grading, I will perform a clean clone of your repo, change
directory into bigdata-assignments/assignment3/ and build
your code:
$ mvn clean package
Your code should build successfully. I am then going to run your
code on the bible+shakes.nopunc collection:
$ hadoop jar target/assignment3-1.0-SNAPSHOT-fatjar.jar edu.umd.YOUR_USERNAME.BuildInvertedIndexCompressed \ -input bible+shakes.nopunc -output index-shakes -numReducers 1 $ hadoop jar target/assignment3-1.0-SNAPSHOT-fatjar.jar edu.umd.YOUR_USERNAME.BooleanRetrievalCompressed \ -index index-shakes -collection bible+shakes.nopunc
The index should build properly (the size should match your answer to Question 1), and the output of the boolean retrieval should be correct.
I am next going to test your code on
the simplewiki-20141222-pages-articles.txt
collection:
$ hadoop jar target/assignment3-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.BuildInvertedIndexCompressed \ -input /shared/simplewiki-20141222-pages-articles.txt -output index-enwiki -numReducers 1 $ hadoop jar target/assignment3-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.BooleanRetrievalCompressed \ -index index-enwiki -collection /shared/simplewiki-20141222-pages-articles.txt
The index should build properly (the size should match your answer
to Question 2). The output of BooleanRetrievalCompressed
should match your answer to Question 3 above.
When you've done everything, commit to your repo and remember to push back to origin. You should be able to see your edits in the web interface. Before you consider the assignment "complete", I would recommend that you verify everything above works by performing a clean clone of your repo and going through the steps above.
That's it! There's no need to send me anything—I already know your username from the first assignment. Note that everything should be committed and pushed to origin before the deadline (before class on February 23). Git timestamps your commits and so I can tell if your assignment is late.
Grading
The entire assignment is worth 40 points:
- The implementation of
BuildInvertedIndexCompressedis worth 20 points: index compression is worth 10 points and making sure the algorithm is scalable is worth 10 points. - The implementation of
BooleanRetrievalCompressedis worth 10 points. - Getting your code to run is worth 10 points. That is, to earn all 10 points, I should be able to run your code (building and running), following exactly the procedure above. Therefore, if all the answers are correct and the implementation seems correct, but I cannot get your code to build and run, you will only get a score of 30/40.
Assignment 4: Graphs due 6:00pm March 23
Begin by setting up your development environment. The process is
exactly the same as in the previous assignment. In your GitHub
repo bigdata-assignments/, create a Maven project with
the following command:
$ mvn archetype:create -DgroupId=edu.umd.YOUR_USERNAME -DartifactId=assignment4
For YOUR_USERNAME, please use your GitHub
username. Once you've executed the above command, change directory
to bigdata-assignments/assignment4. In that directory,
replace pom.xml with this
version here (which is set up
properly for Hadoop). However, inside pom.xml, change the
following line and replace my username with yours.
<groupId>edu.umd.jimmylin</groupId>
Also, replace all instances of assignment1 with
assignment4.
Begin this assignment by taking the time to understand the PageRank reference implementation in Cloud9. There is no need to try the exercise from scratch, but study the code carefully to understand exactly how it works.
For this assignment, you are going to implement multiple-source personalized PageRank. As we discussed in class, personalized PageRank is different from ordinary PageRank in a few respects:
- There is the notion of a source node, which is what we're computing the personalization with respect to.
- When initializing PageRank, instead of a uniform distribution across all nodes, the source node gets a mass of one and every other node gets a mass of zero.
- Whenever the model makes a random jump, the random jump is always back to the source node; this is unlike in ordinary PageRank, where there is an equal probability of jumping to any node.
- All mass lost in the dangling nodes are put back into the source node; this is unlike in ordinary PageRank, where the missing mass is evenly distributed across all nodes.
This assignment can be completed entirely in your VM. Alternatively, you are welcome to use the UMIACS cluster if you wish.
Here are some publications about personalized PageRank if you're interested. They're just provided for background; neither is necessary for completing the assignment.
- Daniel Fogaras, Balazs Racz, Karoly Csalogany, and Tamas Sarlos. (2005) Towards Scaling Fully Personalized PageRank: Algorithms, Lower Bounds, and Experiments. Internet Mathematics, 2(3):333-358.
- Bahman Bahmani, Abdur Chowdhury, and Ashish Goel. (2010) Fast Incremental and Personalized PageRank. Proceedings of the 36th International Conference on Very Large Data Bases (VLDB 2010).
Your implementation is going to run multiple personalized PageRank
computations in parallel, one with respect to each source. The user is
going to specify on the command line the sources. This means that each
PageRank node object (i.e., Writable) is going to contain
an array of PageRank values.
Here's how the implementation is going to work; it largely follows the reference implementation in the exercise above. It's your responsibility to make your implementation work with respect to the command-line invocations specified below.
First, the user is going to convert the adjacency list into PageRank node records:
$ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.BuildPersonalizedPageRankRecords \ -input sample-large.txt -output YOURNAME-PageRankRecords -numNodes 1458 -sources 9627181,9370233,10207721
Note that we're going to use the "large" graph from the exercise
linked above. The -sources option specifies the source
nodes for the personalized PageRank computations. In this case, we're
running three computations in parallel, with respect to node
ids 9627181, 9370233, and 10207721. You can expect the option value to
be in the form of a comma-separated list, and that all node ids
actually exist in the graph. The list of source nodes may be
arbitrarily long, but for practical purposes I won't test your code
with more than a few.
Since we're running three personalized PageRank computations in parallel, each PageRank node is going to hold an array of three values, the personalized PageRank values with respect to the first source, second source, and third source. You can expect the array positions to correspond exactly to the position of the node id in the source string.
Next, the user is going to partition the graph and get ready to iterate:
$ hadoop fs -mkdir YOURNAME-PageRank $ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.PartitionGraph \ -input YOURNAME-PageRankRecords -output YOURNAME-PageRank/iter0000 -numPartitions 5 -numNodes 1458
This will be standard hash partitioning.
After setting everything up, the user will iterate multi-source personalized PageRank:
$ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.RunPersonalizedPageRankBasic \ -base YOURNAME-PageRank -numNodes 1458 -start 0 -end 20 -sources 9627181,9370233,10207721
Note that the sources are passed in from the command-line again. Here, we're running twenty iterations.
Finally, the user runs a program to extract the top ten personalized PageRank values, with respect to each source.
$ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.ExtractTopPersonalizedPageRankNodes \ -input YOURNAME-PageRank/iter0020 -top 10 -sources 9627181,9370233,10207721
The above program should print the following answer to stdout:
Source: 9627181 0.43721 9627181 0.10006 8618855 0.09015 8980023 0.07705 12135350 0.07432 9562469 0.07432 10027417 0.01749 9547235 0.01607 9880043 0.01402 8070517 0.01310 11122341 Source: 9370233 0.42118 9370233 0.08627 11325345 0.08378 11778650 0.07160 10952022 0.07160 10767725 0.07160 8744402 0.03259 10611368 0.01716 12182886 0.01467 12541014 0.01467 11377835 Source: 10207721 0.38494 10207721 0.07981 11775232 0.07664 12787320 0.06565 12876259 0.06543 8642164 0.06543 10541592 0.02224 8669492 0.01963 10940674 0.01911 10867785 0.01815 9619639
Additional Specifications
To make the final output easier to read, in the
class ExtractTopPersonalizedPageRankNodes, use the
following format to print each (personalized PageRank value, node id)
pair:
String.format("%.5f %d", pagerank, nodeid)
This will generate the final results in the same format as above. Also note: print actual probabilities, not log probabilities—although during the actual PageRank computation keeping values as log probabilities is better.
The final class ExtractTopPersonalizedPageRankNodes
does not need to be a MapReduce job (but it does need to read from
HDFS). Obviously, the other classes need to run MapReduce jobs.
The reference implementation of PageRank in Cloud9 has many options: you can either use in-mapper combining or ordinary combiners. In your implementation, choose one or the other. You do not need to implement both options. Also, the reference implementation has an option to either use range partitioning or hash partitioning: you only need to implement hash partitioning. You can start with the reference implementation and remove code that you don't need (see #2 below).
Hints and Suggestion
To help you out, there's a small helper program in Cloud9 that computes personalized PageRank using a sequential algorithm. Use it to check your answers:
$ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.cloud9.example.pagerank.SequentialPersonalizedPageRank \ -input sample-large.txt -source 9627181
Note that this isn't actually a MapReduce job; we're simply using
Hadoop to run the main for convenience. The values from
your implementation should be pretty close to the output of the above
program, but might differ a bit due to convergence issues. After 20
iterations, the output of the MapReduce implementation should match to
at least the fourth decimal place.
This is complex assignment. I would suggest breaking the implementation into the following steps:
- First, copy the reference PageRank implementation into your own assignments repo (renaming the classes appropriately). Make sure you can get it to run and output the correct results with ordinary PageRank.
- Simplify the code; i.e., if you decide to use the in-mapper combiner, remove the code that works with ordinary combiners.
- Implement personalized PageRank from a single source; that is, if
the user sets option
-sources w,x,y,z, simply ignorex,y,zand run personalized PageRank with respect tow. This can be accomplished with the existingPageRankNode, which holds a single floating point value. - Extend the
PageRankNodeclass to store an array of floats (length of array is the number of sources) instead of a single float. Make sure single-source personalized PageRank still runs. - Implement multi-source personalized PageRank.
In particular, #3 is a nice checkpoint. If you're not able to get the multiple-source personalized PageRank to work, at least completing the single-source implementation will allow me to give you partial credit.
Turning in the Assignment
When grading, I will perform a clean clone of your repo, change
directory into bigdata-assignments/assignment4/ and build
your code:
$ mvn clean package
Your code should build successfully.
I will test your code by issuing the following commands:
$ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.BuildPersonalizedPageRankRecords \ -input sample-large.txt -output YOURNAME-PageRankRecords -numNodes 1458 -sources RECORDS $ hadoop fs -mkdir YOURNAME-PageRank $ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.PartitionGraph \ -input YOURNAME-PageRankRecords -output YOURNAME-PageRank/iter0000 -numPartitions 5 -numNodes 1458 $ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.RunPersonalizedPageRankBasic \ -base YOURNAME-PageRank -numNodes 1458 -start 0 -end 20 -sources RECORDS $ hadoop jar target/assignment4-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.ExtractTopPersonalizedPageRankNodes \ -input YOURNAME-PageRank/iter0020 -top 10 -sources RECORDS
Where RECORDS stands for a list of node ids of
arbitrary length (although for practical reasons it won't be more than
a few nodes long). This is hidden from you. The final
program ExtractTopPersonalizedPageRankNodes should print
to stdout a list of top 10 nodes with highest personalized PageRank
values with respect to each source node (as above).
In bigdata-assignments/assignment4/assignment4.md,
tell me if you were able to successfully complete the assignment. This
is in case I can't get your code to run, I need to know if it is
because you weren't able to complete the assignment successfully, or
if it is due to some other issue. If you were not able to implement
everything, describe how far you've gotten. Feel free to use this
space to tell me additional things I should look for in your
implementation.
Also, in the
file bigdata-assignments/assignment4/assignment4.md,
run your implementation with respect to the
sources 9470136,9300650. Run 20 iterations. Copy and
paste the top ten personalized PageRank values with respect to each
source in the file. So it should look something like this:
Source: 9470136 ... Source: 9300650 ...
In case I can't get your code to run, the file will at least give me something to look at.
Grading
The entire assignment is worth 35 points:
- The single-source personalized PageRank implementation is worth 10 points.
- That I am able to run the single-source personalized PageRank implementation is worth 5 points.
- The multiple-source personalized PageRank implementation is worth 15 points.
- That I am able to run the multiple-source personalized PageRank implementation is worth 5 points.
For example, if you've only managed to get single-source working,
but I was able to build it and run it successfully, then you'd get 15
points. That is, I put in -sources w,x,y,z as the option,
and your implementation ignores x,y,z but does correctly
compute the personalized PageRank with respect to w.
Assignment 5: HBase due 6:00pm April 6
Begin by setting up your development environment. The process is
exactly the same as in the previous assignments. In your GitHub
repo bigdata-assignments/, create a Maven project with
the following command:
$ mvn archetype:create -DgroupId=edu.umd.YOUR_USERNAME -DartifactId=assignment5
For YOUR_USERNAME, please use your GitHub
username. Once you've executed the above command, change directory
to bigdata-assignments/assignment5. In that directory,
replace pom.xml with this
version here (which is set up
properly for Hadoop and HBase). However, inside pom.xml, change the
following line and replace my username with yours.
<groupId>edu.umd.jimmylin</groupId>
Note that the link to the pom.xml above is not
the same as the ones from the previous assignments, since in this case
we need to pull in the HBase-related artifacts.
Start off by running HBaseWordCount
and HBaseWordCountFetch in
package edu.umd.cloud9.example.hbase of
Cloud9. Make sure you've pulled the latest master branch in
the Cloud9 repo, because those classes are relatively new
additions.
The program HBaseWordCount is like the basic word
count demo (from Assignment 0), except that it stores the output in an
HBase table. That is, the reducer output is directly written to an
HBase table: the word serves as the row key, "c" is the column family,
"count" is the column qualifier, and the value is the actual count. As
we discussed in class, this allows clients random access to data
stored in HDFS.
The program HBaseWordCountFetch illustrates how you
can fetch these counts out of HBase and shows you how to use the basic
HBase "get" API.
Study these two programs to make sure you understand how they work. Make sure you can run both programs.
NOTE: Since HBase is a shared resource across the
cluster, please make your tables unique by using your username
as part of the table name. Don't just name your
table index, because that's likely to conflict to someone
else's table; instead, name the table index-USERNAME.
In this assignment, you will start from
the inverted
indexing exercise
and boolean
retrieval exercise in Cloud9 and modify the programs to
use HBase as the storage backend. You can start from the solutions
that are already checked in the repo. Specifically, you will write two
programs, BuildInvertedIndexHBase
and BooleanRetrievalHBase:
BuildInvertedIndexHBase is the HBase version
of BuildInvertedIndex from the inverted indexing exercise
above. Instead of writing the index to HDFS, you will write the index
to an HBase table. Use the following table structure: the term will be
the row key. Your table will have a single column family called
"p". In the column family, each document id will be a column
qualifier. The value will be the term frequency.
Something for you to think about: do you need reducers?
BooleanRetrievalHBase is the HBase version
of BooleanRetrieval from the boolean retrieval exercise
above. This program should read postings from HBase. Note that the
only thing you need to change is the
method fetchDocumentSet: instead of reading from
the MapFile, you'll read from the HBase. You shouldn't
need to change anything else in the code.
Turning in the Assignment
When grading, I will perform a clean clone of your repo, change
directory into bigdata-assignments/assignment5/ and build
your code:
$ mvn clean package
Your code should build successfully. I am then going to run your
code on the bible+shakes.nopunc collection:
$ hadoop jar target/assignment5-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.BuildInvertedIndexHBase \ -input bible+shakes.nopunc -output index-bibleshakes-jimmylin $ hadoop jar target/assignment5-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.BooleanRetrievalHBase \ -collection bible+shakes.nopunc -index index-bibleshakes-jimmylin
Of course, I will substitute your username
for jimmylin. The output of the second command should be
the same as the output of BooleanRetrieval in
Cloud9. Therefore, if you get the same results you'll know
that your implementation is correct.
I will then run your code on the simplewiki dataset:
$ hadoop jar target/assignment5-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.BuildInvertedIndexHBase \ -input /shared/simplewiki-20141222-pages-articles.txt -output index-simplewiki-jimmylin $ hadoop jar target/assignment5-1.0-SNAPSHOT-fatjar.jar edu.umd.jimmylin.BooleanRetrievalHBase \ -collection /shared/simplewiki-20141222-pages-articles.txt -index index-simplewiki-jimmylin
Finally, in the
file bigdata-assignments/assignment5/assignment5.md,
answer these two questions:
1. What is the scalability issue with this particular HBase table design?
2. How would you fix it? You don't need to actually implement the solution; just outline the design of both the indexer and retrieval engine that would overcome the scalability issues in the previous question.
The answer to each shouldn't be longer than a couple of paragraphs.
Grading
The entire assignment is worth 35 points:
- Question 1 is worth 5 points.
- Question 2 is worth 5 points.
- The implementation to
BuildInvertedIndexHBaseis worth 10 points; the implementation toBooleanRetrievalHBaseis worth 5 points. - Getting your code to run is worth 10 points. That is, to earn all 10 points, I should be able to run your code (building and running), following exactly the procedure above. Therefore, if all the answers are correct and the implementation seems correct, but I cannot get your code to build and run, you will not earn these points.
Assignment 6: Project Proposal due 6:00pm April 13
We've already discussed in class my expectations for the final project, but as a quick recap:
- Your final project can be on anything related to big data; it does not need to be limited to MapReduce.
- You may work in groups up to three people.
By April 13, you will send me an email outlining your project idea and the composition of your team (or let me know if you are working alone). Only one email per group is necessary. I will provide feedback on the scope and offer other helpful suggestions. Feel free to send me your project ideas earlier if you wish.
Assignment 7: Data Analytics due 6:00pm April 20
Pig, Hive, and Spark Demo
To begin, follow these steps to replicate the demo I showed in class. These commands should be performed inside the Cloudera VM.
First, let's break up our usual collection into two parts:
$ head -31103 bible+shakes.nopunc > bible.txt $ tail -125112 bible+shakes.nopunc > shakes.txt
Put these two files into HDFS.
Pull up a shell and type pig, which will drop you into
the "Grunt" shell. You can interactively input the Pig script that I
showed in class:
a = load 'bible.txt' as (text: chararray); b = foreach a generate flatten(TOKENIZE(text)) as term; c = group b by term; d = foreach c generate group as term, COUNT(b) as count; store d into 'cnt-pig-bible'; p = load 'shakes.txt' as (text: chararray); q = foreach p generate flatten(TOKENIZE(text)) as term; r = group q by term; s = foreach r generate group as term, COUNT(q) as count; store s into 'cnt-pig-shakes'; x = join d by term, s by term; y = foreach x generate d::term as term, d::count as bcnt, s::count as scnt; z = filter y by bcnt > 10000 and scnt > 10000; dump z;
The first part performs word count on the bible portion of the
collection, the second part performs word count on the Shakespeare
portion of the collection, and the third part joins the terms from
both collections and retains only those that occur over 10000 times in
both parts (basically, stopwords). Note that the store
command materializes data onto HDFS, so you can use normal HDFS
commands to look at the results in cnt-pig-bible/
and cnt-pig-shakes/. The dump command outputs to
console.
A neat thing you can do in Pig is to use the describe
command to print out the schema for each alias, as in describe
a.
Next, let's move onto Hive. Type hive to drop into the
Hive shell. Type show tables to see what happens. There
shouldn't any tables.
Let's create two tables and populate them with the word count information generated by Pig:
create table wordcount_bible (term string, count int) row format delimited fields terminated by '\t' stored as textfile; load data inpath '/user/cloudera/cnt-pig-bible' into table wordcount_bible; create table wordcount_shakes (term string, count int) row format delimited fields terminated by '\t' stored as textfile; load data inpath '/user/cloudera/cnt-pig-shakes' into table wordcount_shakes;
After that, we can issue SQL queries. For example, this query does the same thing as the Pig script above:
SELECT b.term, b.count, s.count FROM wordcount_bible b JOIN wordcount_shakes s ON b.term = s.term WHERE b.count > 10000 AND s.count > 10000 ORDER BY term;
Go ahead and play around with Hive by issuing a few more SQL queries.
Another thing to note, as we discussed in class: the actual contents of the Hive tables are stored in HDFS, e.g.:
$ hadoop fs -ls /user/hive/warehouse
Next, let's turn to Spark, which is already installed on your VM. There are two modes to start the Spark shell. The first:
$ spark-shell
This starts Spark in local mode (i.e., doesn't connect to the YARN cluster). Thus, all file reads and writes are to local disk, not HDFS.
The alternative is to start the Spark shell on YARN:
$ export HADOOP_CONF_DIR=/etc/hadoop/conf $ spark-shell --master yarn-client --num-executors 1
The additional export command is to deal
with this
issue in CDH 5.3.0.
Running Spark on YARN creates a more "authentic" experience (e.g., all data input/output goes through HDFS) but adds overhead. Your choice as to which mode you use.
The Spark equivalent to the above Pig script is as follows:
val shakes = sc.textFile("shakes.txt")
val shakesWordCount = shakes.flatMap(l => l.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
shakesWordCount.saveAsTextFile("cnt-spark-shakes")
val bible = sc.textFile("bible.txt")
val bibleWordCount = bible.flatMap(l => l.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
bibleWordCount.saveAsTextFile("cnt-spark-bible")
val joined = shakesWordCount.join(bibleWordCount)
val results = joined.filter( s => s._2._1 > 10000 && s._2._2 > 10000).collect()
The general structure is the same: we perform word count on each of
the collections, and then join the results together. In the word
count, we first tokenize (in the flatMap), then generate
individual counts (in the map), finally group by and sum
(in the reduceByKey).
In Spark, join takes (K, V1)
and (K, V2) to give you (K, (V1,
V2)). The ._1, ._2 are Scala's
notation to access fields in the tuple, e.g., s._2._1
refers to V1 in the joined structured,
and s._2._2 reers to V2 in the joined
structure.
Finally, two helpful methods are collect()
(e.g., results.collect()), which brings all data
into the shell so that you can examine them, and take(n),
which allows you to sample n values.
The Assignment
In this assignment, you'll be working with a collection of tweets on the UMIACS cluster. You are still advised to do initial development and testing within your VM, but the actual assignment will require running code on the UMIACS cluster.
On the UMIACS cluster, in HDFS
at /shared/tweets2011.txt, you'll find a
collection of 16.1 million tweets, totaling 2.3 GB. These are tweet
randomly sampled from January 23, 2011 to February 8, 2011
(inclusive). The tweets are stored as TSV, with the following fields:
tweet id, username, creation time, tweet text.
On this dataset, you will perform two analyses:
- Compute the tweet volume on an hourly basis (i.e., number of
tweets per hour) for the time period from 1/23 to 2/8,
inclusive—that's a total of 408 data points. Note that there are
tweets in the dataset outside this time range: ignore them. You'll end
up with output along these lines (counts are completely made up):
1/23 00 37401 1/23 01 36025 1/23 02 35968 ... 2/08 23 30115
Plot this time series, with time on the x axis and volume on the y axis. Use whatever tool you're comfortable with: Excel, gnuplot, Matlab, etc. Compute the tweet volume on an hourly basis for tweets that contain either the word Egypt or Cairo: same as above, except that we're only counting tweets that contain those two terms (note that this dataset contains the period of the Egyptian revolution). Also plot this time series, with time on the x axis and volume on the y axis.
For the purposes of this assignment, don't worry about matching word boundaries and interior substrings of longer words; simply match the following regular expression pattern:
.*([Ee][Gg][Yy][Pp][Tt]|[Cc][Aa][Ii][Rr][Oo]).*
You are going to perform these two analyses using two approaches: Pig and Spark. Then you'll compare and contrast the two approaches.
| Important | Feel free to play with the Twitter data on the cluster. However, you cannot copy this dataset out of the cluster (e.g., onto your personal laptop). If you want to play with tweets, come talk to me and we'll make separate arrangements. |
Hints and Suggestion
Most of the Pig you'll need to learn to complete this assignment is contained in the demo above. Everything else you need to know is contained in these two links:
I would suggest doing development inside your VM for faster iteration and run your code on the cluster only once you've debugged everything.
When you type pig to drop into the "Grunt" shell, it
will automatically connect you to the Hadoop (both in the VM or on the
UMIACS cluster). However, for learning Pig, "local mode" is useful: in
local mode, Pig does not execute scripts on Hadoop, but rather on the
local machine, so it's a lot faster when you're playing around with
toy datasets. To get into local mode type pig -x
local. Note that in local mode your paths refer to local disk
and not HDFS.
Since you're not allowed to copy the Twitter data out of the cluster, when you're developing in your VM, simply make up some test data.
Similarly, most of the Spark you'll need to complete this assignment is provided in the demo above. In addition, you'll find this Spark programming guide helpful. There are plenty of guides and tutorials on the web on Scala in general — just search for them.
Like Pig, you can run Spark in "local" mode or using the YARN
cluster (using the --master yarn-client option). Local
model is helpful for debugging and interactively manipulating
data. When running over the entire collection on the UMIACS cluster,
feel free to set --num-executors 10, which should give
you an adequate degree of parallelism. However, please don't set the
value greater than 10, as you will be occupying too much capacity on
the cluster and may prevent others from also running Spark.
Turning in the Assignment
In your GitHub repo bigdata-assignments/, create a
directory named assignment7/.
In bigdata-assignments/assignment7/assignment7.md, put
the two Pig scripts for analysis #1 and analysis #2 and the two Spark
scripts for analysis #1 and analysis #2. The output of these two
scripts should be the same. In the
directory MapReduce-assignments/assignment7/, there
should be four text files:
hourly-counts-pig-all.txthourly-counts-pig-egypt.txthourly-counts-spark-all.txthourly-counts-spark-egypt.txt
These text files should contains the results of analysis #1 and analysis #2 using Pig and Spark.
Finally, in the
directory MapReduce-assignments/assignment7/, there
should be two plots (i.e., graphics
files), hourly-counts-all
and hourly-counts-egypt that plots the time series. The
extensions of the two files should be whatever graphics format is
appropriate, e.g., .png. Use whatever tool you're
comfortable with: Excel, gnuplot, Matlab, etc.
Grading
The entire assignment is worth 25 points:
- 10 points for the Pig implementations.
- 10 points for the Spark implementations.
- 5 points for the plots.
Final Project presentations on May 4 and May 11
There will be two deliverables for the final project: a presentation and a final project report. In more detail:
- The final project report is due on May 11. I expect the report to describe the problem you're trying to solve (i.e., motivation), how you went about solving it (i.e., methodology and algorithm design, etc.), and how well your solution works (i.e., experimental results and evaluation). Use the ACM templates. I'm expecting a report of around 5-6 pages in the ACM format. Send the final project report to me over email; include your presentation slides also.
- The presentations will take place during class on May 4 and May 11. For an individual project, you'll get up to 15 minutes for the presentation; for a group project you'll get up to 20 minutes for the presentation. Your presentation should cover the same aspects of the project mentioned above, but if you're giving your presentation in the earlier class session (May 4), it's okay not to have complete results yet (although I'd hope you have some preliminary results).