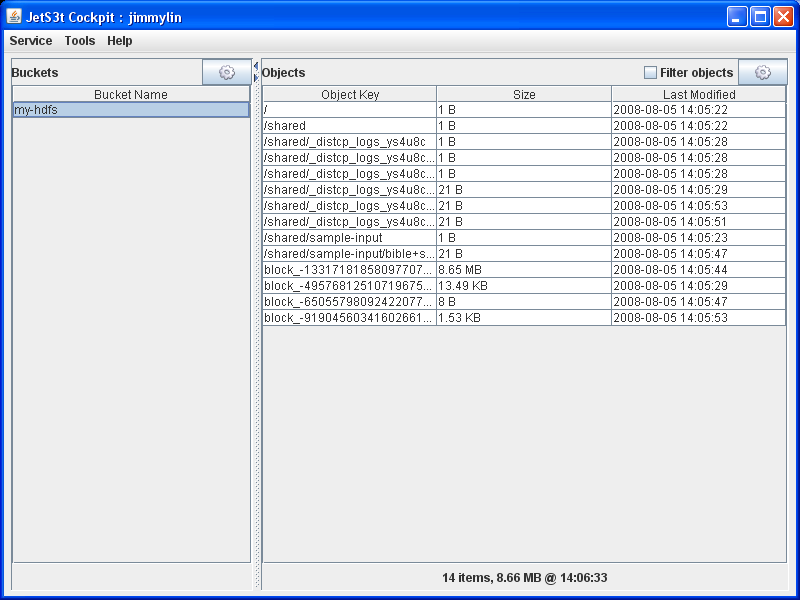
This tutorial will get you started with Amazon's S3. Before you begin, first complete the tutorial on downloading Cloud9 and getting started with EC2. By the end of this tutorial, you will have successful transferred files between HDFS and S3.
To understand what we're doing, let's address the obvious question: why do we need S3? The issue with EC2 is that all your data disappear after you tear down your instances. Puff—just like that, vanished into the bit bucket (sorry, mixing metaphors here). Of course, you can scp data over, and you can scp data back onto your local machine. Unfortunately, not only is this slow, but Amazon charges you for inbound and outbound bandwidth. The solution: enter S3, which is a persistent store that works in conjunction with EC2. There are no charges for transferring data between EC2 and S3. Ah, but here's the catch: S3 charges by the GB per month. Ultimately, they get you one way or another—it's like shipping and handling in those infomercials. Nevertheless, the point is that moving data between EC2 and S3 is quite convenient, and much faster than scp.
Before we begin, a few notes:
- For writing these instructions I used Hadoop 0.17.0 and Sun's Java JDK 1.6.0_06 on Windows XP (with Cygwin). However, these instructions should be applicable to other operating systems.
- Note that I'm showing commands as they apply to me: you'll have to change paths, name of machines, etc. as appropriate.
- In capturing traces of commands running, I use the convention of [...] to indicate places where the output has been truncated.
- You'll be typing a lot of commands on the command-line. What I've found helpful is to keep a text file open to keep track of the commands I've entered. This is useful for both fixing inevitable typos in command-line arguments and for retracing your steps later.
- It is best to allocate an uninterrupted block of time to this tutorial, because once you start up an EC2 cluster, you're being charged by time.
Just to give you an overview, here are the steps:
- Step 0: Download JetS3t and prep S3
- Step 1: Copying stuff out of HDFS in S3
- Step 2: Copying stuff into HDFS from S3
- Postscript
Let's get started!