You'll want to
consult Running
Hadoop on Amazon EC2 for reference, but I'll summarize the
instructions below. To begin, make sure you're working with Hadoop
0.20.1 (stock Apache distribution) and have the EC2 environment
variables properly set (see previous step). Note that all the Amazon
tools begin with "ec2-", which distinguishes them from tools bundle in
the Hadoop distribution.
In case you are curious, here's how you find all available Hadoop
images with the Amazon EC2 tool.
$ ec2-describe-images -x all | grep hadoop
You'll be surprised at how many Hadoop AMIs there are!
Open the file
hadoop-0.20.1/src/contrib/ec2/bin/hadoop-ec2-env.sh.
Fill in the following variables with information from you own
account:
- AWS_ACCOUNT_ID (no dashes)
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
If you're using Cygwin, you may also want to tweak the following
variables:
- MASTER_PRIVATE_IP_PATH
- MASTER_IP_PATH
- MASTER_ZONE_PATH
These files store information about the cluster you've started up.
The variables have paths containing ~, which in Windows will map to
something like "C:\Documents and Settings\...". That's a path
containing spaces, which breaks some of the Hadoop EC2 scripts.
For Cygwin users only: As previously mentioned, the Hadoop
EC2 scripts are not very Windows-friendly. If you don't implement the
below workaround, you'll get the following error.
Invalid argument for option '-f, --user-data-file DATA-FILE': '/cygdrive/c/...' (-h for usage)
The issue is that USER_DATA_FILE, defined in hadoop-ec2-env.sh,
needs to be passed in as a parameter to the EC2 startup scripts.
Something strange about Cygwin screws that up. To fix the problem,
you'll need to go into hadoop-0.20.1/src/contrib/ec2/bin. On line 88
of launch-hadoop-master, you'll see this following line:
INSTANCE=`ec2-run-instances ... -f "$bin"/$USER_DATA_FILE ...
Remove the "$bin" so that it reads:
INSTANCE=`ec2-run-instances ... -f $USER_DATA_FILE ...
On line 53, of launch-hadoop-slaves, you'll see this following line:
ec2-run-instances ... -f "$bin"/$USER_DATA_FILE.slave ...
Remove the "$bin" so that it reads:
ec2-run-instances ... -f $USER_DATA_FILE.slave ...
<end Cygwin workaround>
Open a shell and go to hadoop-0.20.1/src/contrib/ec2/bin. Launch a EC2
cluster and start Hadoop with the following command. You must supply a
cluster name (test-cluster) and the number of slaves (2 in my
case). At this point, it makes no sense to start up a large cluster
(even if you can!)—one or two nodes is sufficient. After the
cluster boots, the public DNS name will be printed to the console.
$ ./hadoop-ec2 launch-cluster test-cluster 2
Testing for existing master in group: test-cluster
Starting master with AMI ami-fa6a8e93
Waiting for instance i-961a15fe to start
..................Started as domU-12-31-39-02-61-03.compute-1.internal
Warning: Permanently added 'ec2-75-101-178-200.compute-1.amazonaws.com,75.101.178.200' (RSA) to the list of known hosts.
Copying private key to master
id_rsa-gsg-keypair 100% 1694 1.7KB/s 00:00
/cygdrive/c/ec2/hadoop-0.20.1/src/contrib/ec2/bin/launch-hadoop-master: line 119: dig: command not found
Master is ec2-75-101-178-200.compute-1.amazonaws.com, ip is , zone is us-east-1c.
Adding test-cluster node(s) to cluster group test-cluster with AMI ami-fa6a8e93
i-ec191684
i-ee191686
Note: In Cygwin, the script may complain about not being
able to find the dig DNS utility (as with above). There doesn't
appear to be a standard Cygwin package that contains the utility, but
not having it is okay (you'll notice that the actual IP address for
the cluster is missing). Don't worry about it.
The meter has just started running... so you're being billed for
usage starting now. After a little bit, you should be able to access
the jobtracker webapp on port 50030 of the master, which in my case
is:
http://ec2-75-101-178-200.compute-1.amazonaws.com:50030/
Obviously, your master will have a different public address. Now
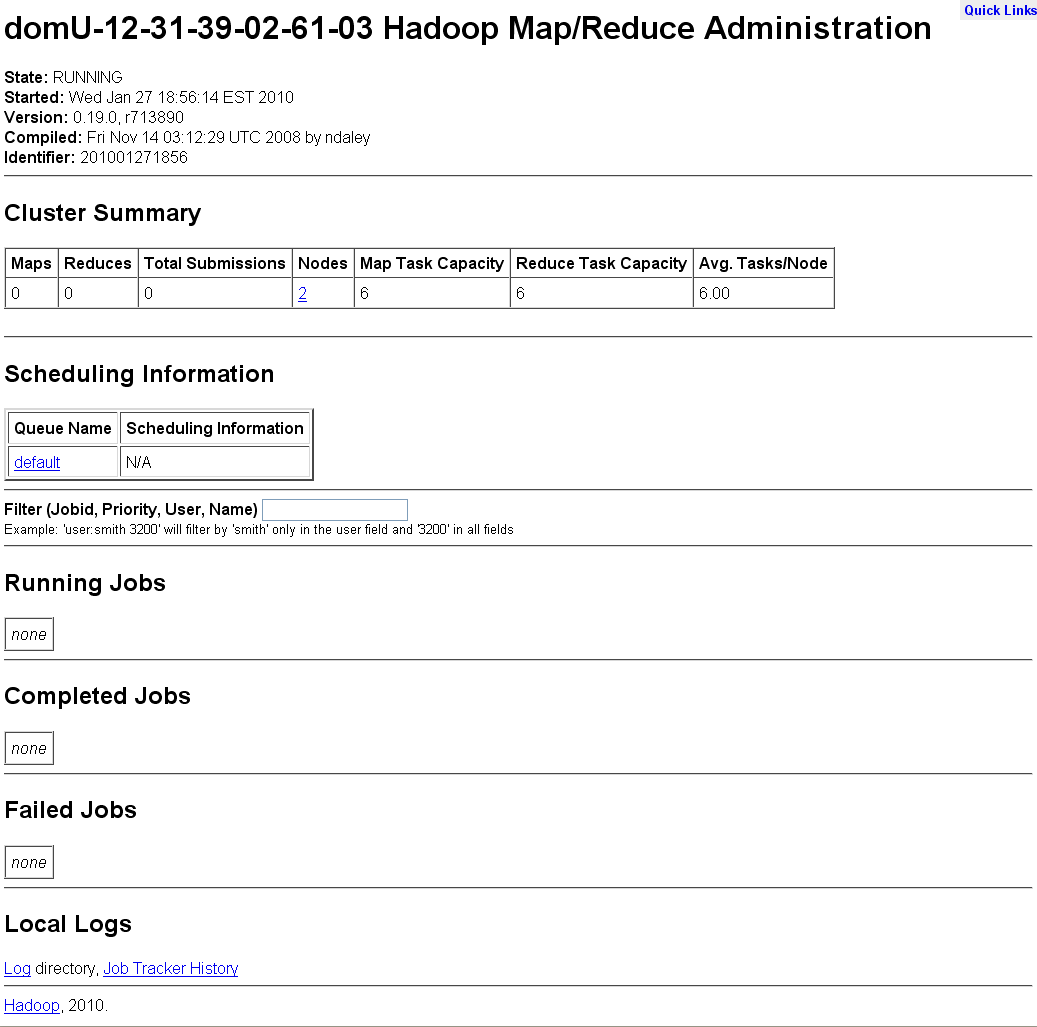
navigate to that URL in a browser, and you should see something
like this screenshot of the jobtracker
webapp.
Congratulations, you've just started a Hadoop cluster in the
clouds! You'll notice that the cluster is actually running Hadoop
0.19.0. Unfortunately, that's the most recently available AMI (as of
Jan. 2010). Under "Nodes", you should see 2, since we started up two
slaves. If the number of nodes is 0, the slaves are probably booting
up... wait a bit and then check again.
You can use the EC2 tools to see the instances you're running:
$ ec2-describe-instances
RESERVATION r-6e5cc706 613871172339 test-cluster-master
INSTANCE i-961a15fe ami-fa6a8e93 ec2-75-101-178-200.compute-1.amazonaws.com [...]
RESERVATION r-ee5cc786 613871172339 test-cluster
INSTANCE i-ec191684 ami-fa6a8e93 ec2-204-236-192-146.compute-1.amazonaws.com [...]
INSTANCE i-ee191686 ami-fa6a8e93 ec2-75-101-191-132.compute-1.amazonaws.com [...]
Pretty cool, huh?
{kind=link}